2.3 JavaScript:页面运行的核心原理
JavaScript 是前端的核心,是一门应用非常广泛并且正在快速发展的编程语言。早期的 JavaScript 虽然简单好用,但一些细节上的设计可能难以理解,这也是历史原因造成的。ES6 出现后,JavaScript 语法进行了一次大版本的升级,并且迅速应用到现代前端框架中,所以 JavaScript 的面貌焕然一新。
然而,JavaScript 语法虽然在升级,但核心的运行机制并没有改变,依然是单线程基于事件循环执行任务,依然是基于原型的面相对象,这也是 JavaScript 的基础和根本。
本节主要介绍 JavaScript 的核心原理。这部分内容在面试中用得到,可以用来考验程序员的 JavaScript 基础是否深厚。
2.3.1 数据类型与函数
根据存储方式不同,可以把 JavaScript 的数据类型分为基本类型(原始类型)和引用类型(复杂类型)两种。基本类型的结构简单,直接保存在栈内存中;引用类型则保存在堆内存中。
这两种存储方式的差别反映到代码上就是给一个变量赋值时能不能做到完全拷贝。例如,在下面的代码中,当变量 b 改变时,变量 a 是否会改变:
var a = "前端真好玩";
var b = a;
b = "前端真有趣";
console.log("a:", a);
console.log("b:", b);
var a1 = { name: "前端人" };
var b1 = a1;
b1.name = "程序员";
console.log("a1:", a1);
console.log("b1:", b1);在浏览器中执行代码,打印结果如图 2-17 所示:
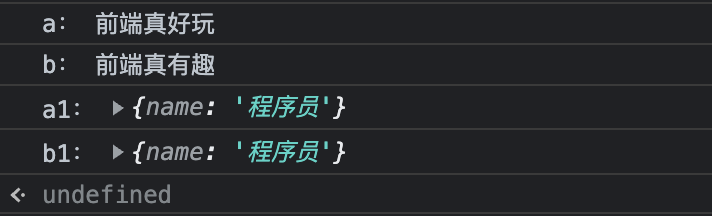
由图 2-17 可以看出,采用同样的赋值方式,修改变量 b 时不会影响变量 a 的值,而修改变量 b1 时会同时修改变量 a1 的值,这看起来很不可思议。其实,在了解了基本类型和引用类型的存储原理后,这个问题将迎刃而解。
JavaScript 中的基本类型共 6 种(Symbol 为 ES 6 新增),具体如下:
String:字符串。Number:数值。Boolean:布尔值。Null:空。Undefined:未定义。Symbol:唯一的值。
这 6 种基本类型可以用 typeof 关键字来判断,方法如下:
typeof "杨成功"; // "string"
typeof 5; // "number"
typeof false; // "boolean"
typeof null; // "object"
typeof undefined; // "undefined"
typeof Symbol(); // "symbol"其中的 5 种类型都可以准确判断,但是 Null 类型的判断结果是“object”,而使用 typeof 关键字判断引用类型时结果也是“object”,这就会比较尴尬。typeof 关键字不能用来判断 Null 类型。
应该如何判断 Null 类型后面会介绍,这里只需要了解其特殊性即可。
很多人可能会混淆 Null 和 Undefined,因为它们看着好像差不多,实际上是有区别的。在语义上,Undefined 表示未定义,即变量没有值;而 Null 表示变量有值,但是是一个空值。
Undefined 表示的是一个声明但未赋值的状态,具体包括以下几种:
- 声明一个变量未赋值
- 访问对象上不存在的属性
- 函数定义了参数但未传参
而 Null 表示被人为设置为空对象。最常见的情况是定义一个变量表示对象,一般由开发者主动赋值,这个变量实际的值会在后面的某个环节设置,此时需要将变量的初始值设置为“Null”。在变量使用完毕需要重置时,再把它赋值为“Null”。
上面提到的对象就是一个引用类型。常见的引用类型分为以下几种:
Object:对象Array:数组Function:函数Date:时间RegExp:正则表达式
我们试着用 typeof 判断引用类型,发现除函数外,其他类型的结果都是 “object”:
typeof console.log; // "function"
typeof {}; // "object"
typeof []; // "object"
typeof new Date(); // "object"到这里我们能得出一个类型判断的结论:typeof 可以判断除 null 外的基本类型和函数。
那除函数外的引用类型,和前面说过基本类型 null 该怎么判断呢?别急,这些无法用 typeof 判断的类型,都可以用 Object 原型对象上的一个方法来判断,这个方法就是:
Object.prototype.toString();为什么可以用 Object 原型对象上的方法呢?这是因为引用类型虽然分为上面几种,但实际上所有的引用类型都继承自 Object 对象。那为什么 Null 也可以这样判断呢?因为 Null 同样继承自 Object 对象,其他基本类型也继承自 Object 对象,这就是 JavaScript 中所说的“万物皆对象”。因此,Object.prototype.toString()方法适用于所有数据类型。
因为 Object.prototype.toString() 是原型上的方法,默认只对 Object 本身有效。如果是继承自该对象的成员使用,那么就要用 call() 方法来改变 this 指向并调用,方法如下:
// 引用类型
Object.prototype.toString.call([]); // "[object Array]"
Object.prototype.toString.call({}); // "[object Object]"
Object.prototype.toString.call(new Date()); // "[object Date]"
Object.prototype.toString.call(/\\/); // "[object RegExp]"
// 基本类型
Object.prototype.toString.call(null); // "[object Null]"
Object.prototype.toString.call("前端"); // "[object String]"
Object.prototype.toString.call(false); // "[object Boolean]"根据返回结果我们已经可以看到区别了。如果希望类型的判断结果和 typeof 保持统一,那么就可以稍微处理一下,写一个获取类型的函数:
function getDataType(data) {
return Object.prototype.toString.call(data).slice(8, -1).toLowerCase();
}
getDataType(null); // null
getDataType([]); // array
getDataType({}); // object使用 Object 判断类型很可靠,但是代码书写上还是有些冗长,不像 typeof 这样一个简单的关键字就能搞定。那么判断引用类型还有更简单的方法吗?
当然有的。除 typeof 外,JavaScript 还有一个专门用来判断引用类型的关键字 —— instanceof。instanceof 的原理是基于原型链判断实例是否继承于某个构造函数,方法如下:
[] instanceof Array; // true
new Date() instanceof Date; // true
var json = {};
json instanceof Object; // true
var fun = () => {};
fun instanceof Function; // true显然这种方式要比 Object 原型判断优雅不少。既然有快捷方法,那么 Object.prototype.toString() 还有存在的必要吗?
其实有的。首先它的兼容性是最好的,可以用来做 Polyfill 兼容方案。再者搞懂了这个方法可以更好的帮助我们理解原型继承的相关知识。
在引用类型中有一个功能强大的类型叫做函数。函数不光是数据类型,更重要的它是一个执行任务的单元。
2.3.2 变量与作用域
上面我们用 var 关键字声明了变量,这个变量可在当前作用域使用 —— 没错,变量是有作用域的。
var 声明的变量作用域可能有两种:全局作用域和函数作用域。全局声明(任意函数之外声明)的变量拥有全局作用域,函数内声明的变量拥有函数作用域,仅在函数内可用。代码如下:
// a.js
var str1 = "北京";
function test() {
var str2 = "上海";
console.log("str1", str1);
}
test();
console.log("str2", str2);上面代码扔到控制台,打印结果如下:
str1 北京
Uncaught ReferenceError: str2 is not defined说明在函数内可以访问到函数外的变量,但在函数外不可以访问到函数内的变量。这是 JavaScript 最基本的作用域机制:如果当前作用域内找不到变量,JS 会“探出头去” 从父级作用域找,有点类似于事件冒泡,一直找到最外层的全局作用域,但却永远不会从子级作用域寻找。
ES6 新增了一个作用域,叫做块级作用域。顾名思义,是一个代码块的作用域,用一对大括号表示。块级作用于必须用新的关键字 let 声明变量,当变量声明在一对大括号之间,这个变量就有了块级作用域。
{
let ciry1 = "上海";
var ciry2 = "成都";
}
console.log(ciry1); // ReferenceError: ciry1 is not defined.
console.log(ciry2); // 成都除了声明块级变量,相比于 var 来说 let 还有其他的特性,代表性的是两个:
- 相同变量名禁止重复声明
- 不存在变量提升
用 var 声明变量,相同变量名是可以重复声明的,这看起来是一个不符合逻辑的操作,然而 JavaScript 并不会报错,只不过是后面声明的变量覆盖了前面的变量。事实上并不是 JavaScript 允许重复声明,而是在这种情况下 JavaScript 做了自动转换,比如:
// 代码书写
var a = 1;
var a = 2;
// JavaScript 转换
var a = 1;
a = 2;转换逻辑很简单,重复声明会自动去掉 var 关键字。不过这种转换带来的问题是,当我们想声明一个新变量,不小心和之前的变量名冲突了,此时旧的变量会在我们不知道的情况下被覆盖,这就带来了隐患。而 let 不允许重复声明,重复声明就会报错,这反而是我们想要的:
function fun() {
let b = 1;
let b = 2; // SyntaxError: Identifier 'b' has already been declared
}let 还有一个特点是不存在变量提升,什么是变量提升?我们看一段代码:
function fun1() {
console.log(str);
}
fun1(); // ReferenceError: str is not defined
function fun2() {
console.log(str);
var str = "烤鸭";
}
fun2(); // undefined函数 fun1 运行结果正常,但是 fun2 打印结果却很奇怪:明明 str 变量是在打印之后声明的,正常情况下这里的结果也应该是 ReferenceError,但是却变成了 undefined,其实这就是变量提升带来的结果。fun2 的代码被 JavaScript 解析之后变成了这样:
function fun2() {
var str;
console.log(str);
str = "烤鸭";
}看到了吧,var 声明的变量会被自动提升到当前作用域的顶层,结果是只要变量被声明,不管是在前在后,访问都不会报错,这也导致初学者很迷惑。let 则去掉了变量提升,异常会正常抛出:
function fun2() {
console.log(str);
let str = "烤鸭";
}
fun2(); // ReferenceError: Cannot access 'str' before initializationES6 新增的第二个声明关键字是 const,表示声明一个常量,常量在声明之后是不可以修改的。同样这个关键字的作用是避免我们误操作覆盖了本不应该变化的数据。而且既然是常量,就要求声明的时候必须赋值,不赋值会报错。
const 有和 let 一样的特性,包括块级作用域,常量不提升,不可重复声明。const 和 let 的组合是 JavaScript 变量声明更标准的实现,建议用 let + const 替代 var 声明。
const 常量不可更改,要对“不可更改”有正确理解。不可更改是指不允许重新赋值,但是对于引用类型,数据本身的更改并不代表重新赋值。比如如下代码:
const str = "迪迦";
str = "盖亚"; // TypeError: Assignment to constant variable.
const arr = [1];
arr.push(2);
console.log(arr); // [1,2]
arr = [1, 2]; // TypeError: Assignment to constant variable.因为对于引用类型,变量/常量存储的都是一个指针,该指针指向堆内存中的真实数据。所以数据本身变化不会导致指针变化,因此修改数据本身,如添加一个数组项,添加一个对象属性,都是可以的。但是如果要给变量重新赋值,则会改变指针,因此同样会报错。
2.3.3 面向对象
众所周知,JavaScript 是一门面向对象的编程语言。但是它又不像 Java 那样是存粹的基于类的面向对象,而是独有的基于原型和原型链实现面向对象。
什么是原型?原型(Prototype)是一种设计模式,它以自己独有的方式实现了继承和复用。具体来说,原型就是一个对象,我们也叫原型对象,原型对象只是一个拥有 constructor 属性的普通对象,没有什么神奇之处,重要的是它通过属性的互相指向从而实现了继承。
看一个简单的声明数组的例子:
var arr = new Array();
// 或者 var arr = []
arr.push("北京");
console.log(arr); // ['北京']上面声明了一个空数组,通过 arr.push() 方法添加了一个元素。但是你有没有想过,这里的 push() 方法从何而来?可能在刚学 JavaScript 的时候你就知道 push() 方法,但是这个方法定义在哪呢?
别急,我们一块找一下:
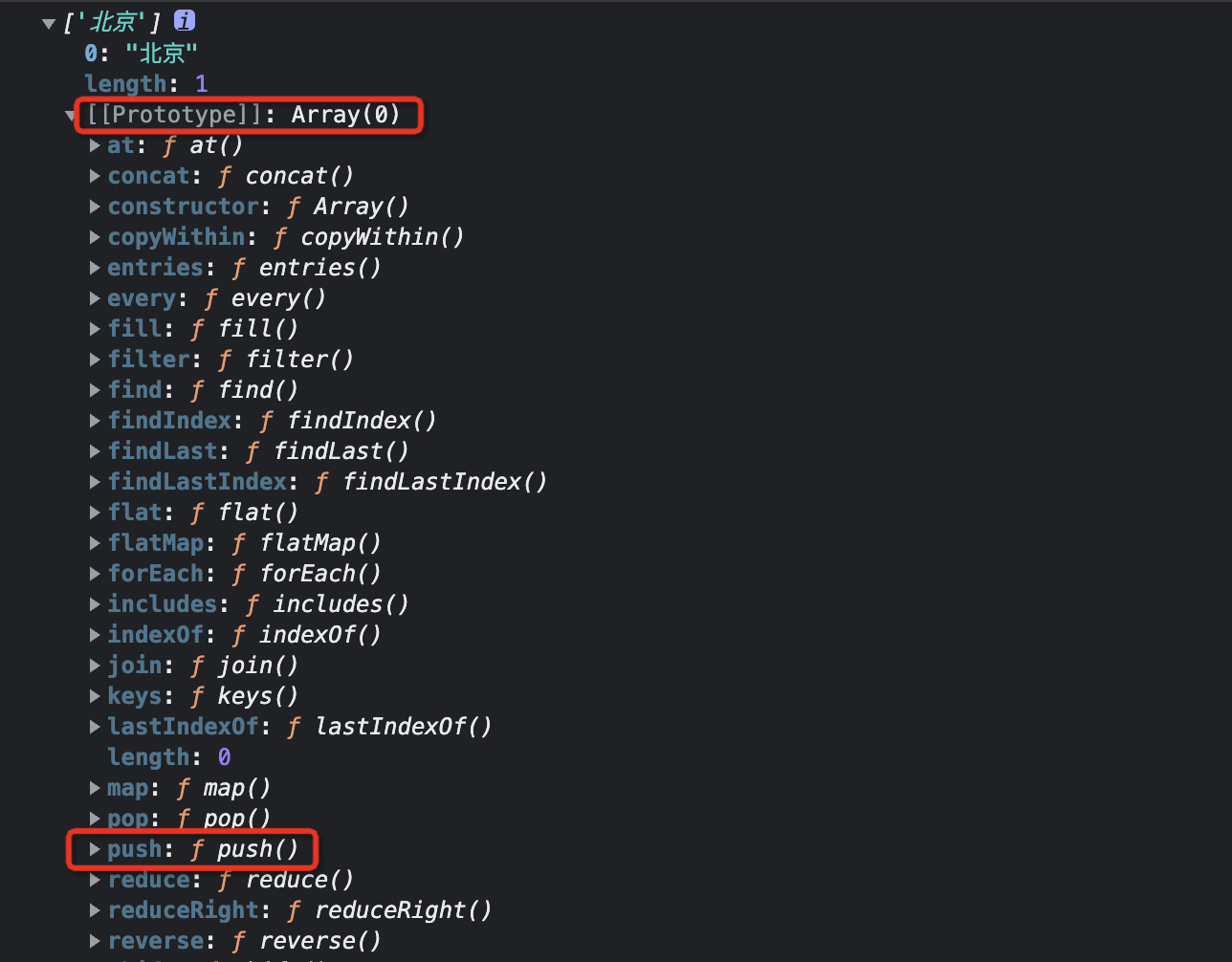
如图所示,数组下有一个 [[Prototype]] 属性,这个属性下定义了一大堆方法,我们可以使用的数组方法都定义在这里,push() 就是其中之一。
事实上,[[Prototype]] 是一个内部属性,不可以显式访问,但是这个属性指向的就是一个原型对象(有 constructor 属性)。
为了方便访问,浏览器厂商实现了一个 __proto__ 属性来指向这个原型对象,这个属性和内部属性 [[Prototype]] 的指向一致,但它是可以直接访问的。因此 push() 方法的调用逻辑如下:
arr.push("北京");
// 等同于
arr.__proto__.push("北京");那这个原型对象从何而来呢?为什么会出现在 arr 变量上?
还是从上面的图中找线索,我们发现 [[Prototype]] 属性后面跟着一个 Array(0),这表示这个内部属性实际上是属于 Array 构造函数。Array 有一个 prototype 属性指向它的原型对象,如下图:
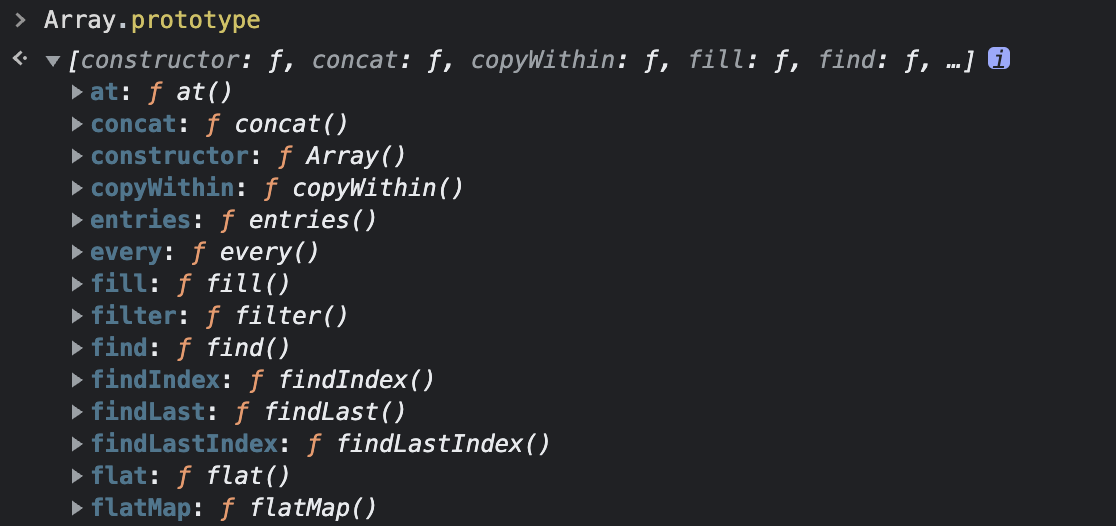
惊喜吧,原来 arr.__proto__ 指向的就是 Array.prototype,也就是它的构造函数 Array 的原型对象,这下搞懂了。开始部分呢我们说过,原型对象有 constructor 属性,从上图能看出来,constructor 属性又指回了 Array 本身。我们在控制台试一下:
Array.prototype.constructor === Array;
// true
arr.__proto__ === Array.prototype;
// true综合上面的实验结果,我们可以得出三点结论:
- 构造函数有 prototype 属性,指向它的原型对象。
- 原型对象中有 construtor 属性,指回构造函数。
- 实例有__proto__属性,指向构造函数的原型对象。
这个结论是理解 JavaScript 面向对象的关键。除此之外,还要特别声明一点:实例本身没有原型对象,只有构造函数才有原型对象,但是实例可以访问到它的构造函数的原型对象。
原型理解了之后,那原型链又是什么呢?
还是接着上面的那个例子,我们再看一个方法就能明白了:
arr.valueOf(); // ['北京']细查 Array 的原型对象 Array.prototype,发现并没有 valueOf() 这个方法,那这里为什么可以执行呢?这个方法在哪?
其实我们可以把 Array.prototype 也看成一个实例对象,这个实例对象和 arr 一样也有一个 __proto__属性,指向它自己的构造函数的原型对象。
我们看看数组原型对象的 __proto__ 是什么:
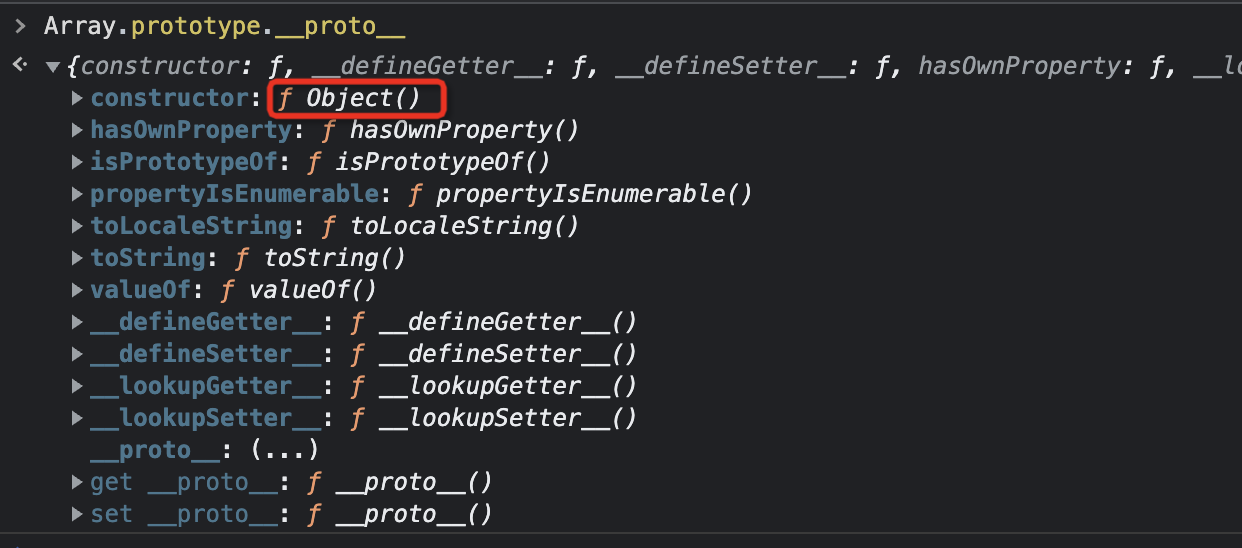
原来 Array.prototype 是数组的原型对象,同时也是 Object 的实例。当 valueOf() 方法在 Array.prototype 上找不到时,它会沿着 __proto__ 属性继续向上找,从而在 Object.prototype 上找到了这个方法。
这种原型之间层层向上找的情况,就组成了一条原型链。根据原型链,我们又可以总结出第四条规律:
- 原型对象也有__proto__属性,指向上上层原型对象,直到原型对象为 null。
因为 Object.prototype.__proto__ == null,而 null 没有原型,是原型链中的最后一个环节。如果所用的方法到这里还没有找到,就会抛出 TypeError 错误。
综合结果:当访问一个 JavaScript 实例的属性/方法时,它首先会搜索这个实例本身;如果找不到,它会转而搜索实例的原型对象;如果还找不到,它就去搜索原型对象的原型对象,一直往上找,这个搜索的轨迹,就叫做原型链。
搞懂了原型与原型链之后,我们自己动手实现一个原型链。假设你有两只小猫,一只叫西西,白色;一只叫兜兜,灰色。两只猫有一个共同的特征,就是喜欢喵喵叫。
我们创建一个构造函数 MyCat 来表示自己的猫仔:
function MyCat(name, color) {
this.name = name;
this.color = color;
}
var xixi = new MyCat("西西", "白色");
var doudou = new MyCat("兜兜", "灰色");
console.log(xixi.name); // 西西
console.log(doudou.color); // 灰色现在两只猫的名字和颜色都设置好了,但是叫(call)这个方法是猫的共同特性,如果定义在函数内部,实例化时会重复创建。根据原型链原理,我们在 MyCat 的原型对象上定义一次即可:
MyCat.prototype.call = function () {
console.log("喵喵喵喵");
};
console.log(xixi.call()); // 喵喵喵喵
console.log(doudou.call()); // 喵喵喵喵现在两只猫都会叫了。假设你之后还准备养一只狗,或者一只乌龟,这些都是你的宠物,你要给他们都做一个标记 —— 主人是你!为了避免重复定义,还要再定义一个函数:
function MyPets() {
this.owner = "小帅";
}那么让你的宠物加上 owner 这个标签呢?非常简单:
MyCat.prototype.__proto__ = MyPets.prototype;
console.log(xixi.owner); // 小帅
console.log(doudou.owner); // 小帅这样我们自己就实现了原型链的继承。
ES6 新增了一个 class 来替代构造函数,更直观的实现了继承,但 class 也只是构造函数的语法糖,只是让原型的写法更加清晰、更像面向对象编程。上述的例子我们用 class 来改造一下:
// 宠物类
class MyPets {
owner = "小帅";
}
// 猫仔类
class MyCat extends MyPets {
constructor(name, color) {
super();
this.name = name;
this.color = color;
}
call() {
console.log("喵喵喵喵");
}
}
var xixi = new MyCat("西西", "白色");
var doudou = new MyCat("兜兜", "灰色");2.3.4 事件循环
如果你想了解 JavaScript 的异步执行机制,那么事件循环一定是你绕不开的话题。事件循环也就是 Event-Loop,我们先看一段经典的异步执行的代码:
console.log(1);
setTimeout(function () {
console.log(2);
});
new Promise(function (resolve) {
console.log(3);
resolve();
})
.then(function () {
console.log(4);
})
.then(function () {
console.log(5);
});
console.log(6);上述代码的打印顺序是什么呢?可以先在脑子里过一遍,并记住结果,然后带着问题解析事件循环。
要了解事件循环,首先要明白 JavaScript 是如何执行的。这里涉及到 3 个重要角色:
函数调用栈宏任务队列(macro-task)微任务队列(micro-task)
JavaScript 代码是分块执行的。每一个需要执行的代码块会被放到一个栈里,按照“后进先出”的顺序执行,这个栈就是函数调用栈。
当 JS 代码第一次执行时,全局代码会被推入调用栈执行。后面每调用一次函数,就会往栈中推一个新的函数并执行。执行完毕后,函数会从栈内弹出。
比如这段简单的代码如下:
console.log("开始");
function test() {
console.log("执行");
}
test();用图表示这段代码在函数调用栈中如何执行:
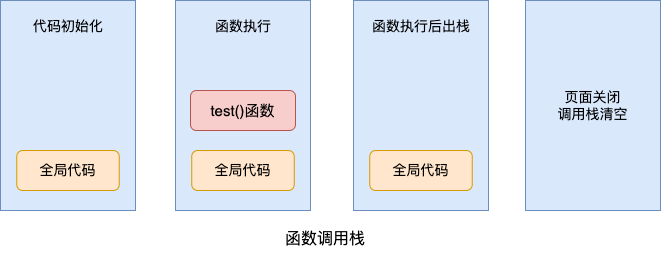
也就是说,代码只有在进入函数调用栈才能被执行的。当一系列函数被推入调用栈后,JavaScript 会从栈顶开始执行函数,执行完一个立刻出栈执行下一个,这个过程会非常快。
但是有一种特殊情况,就是异步任务。当一个函数(或全局代码)内包含异步任务时,比如 setTimeout 的回调函数和 promise.then 的回调函数,这些函数是不能立刻被推入函数调用栈执行的,它得等到某个时间点之后才能决定是否执行。不能立刻执行怎么办?就只能排队等呗。
于是这些等待执行的任务,按照一定的规则排起长队,等待着被推入调用栈。这个由异步任务组成的队列,就叫做“任务队列”。
所谓宏任务(macro-task)与微任务(micro-task),是对任务队列中任务的进一步细分。JavaScript 中哪些任务是宏任务,哪些任务是微任务,请看这张图:
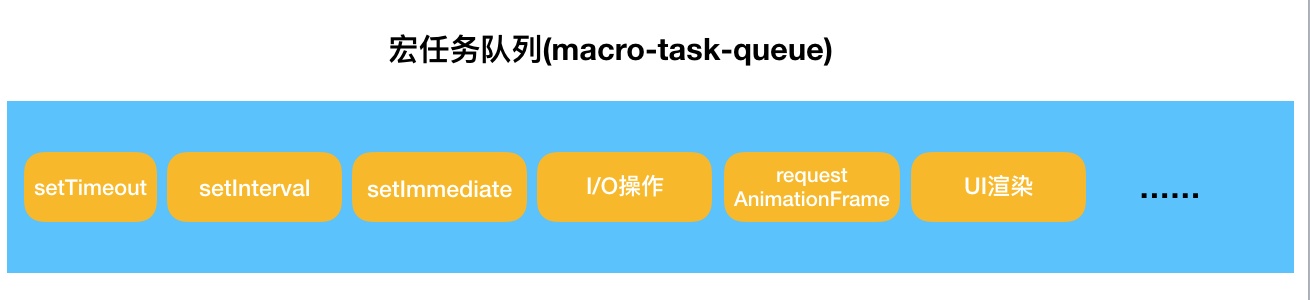
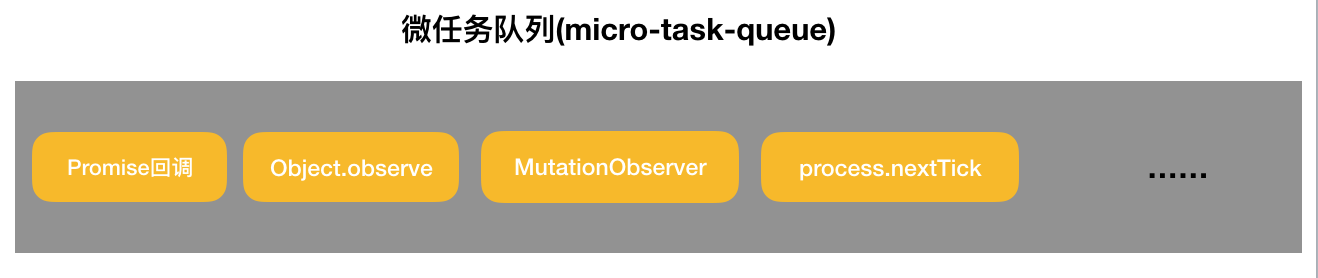
注意:script 脚本(全局代码)也是一个宏任务;此外,宏任务中的 setImmediate、微任务中的 process.nextTick 这些都是 Node.js 独有的。
了解到这里,我们就能解析开头的那道题了。初始情况下,函数调用栈为空,微任务队列空,宏任务队列里有且只有一个 script 脚本(全局代码),是这样的:

第一步,JavaScript 代码运行,宏任务队列里的全局代码率先出列进入调用栈执行,同步代码会按照顺序执行完毕,因此控制台先打印 1,3,6。
为什么 3 也会打印呢?因为 Promise 构造函数的参数是一个同步函数,它会立即执行。后面的 .then 和 .catch 才是真正的异步任务。
在这一步的同步代码执行中,会产生新的宏任务和微任务进入各自的队列,此时的调用栈和队列的情况如下:
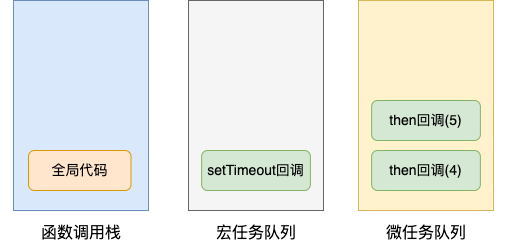
注意:如上图所示,全局代码执行后会一直保存在栈内,不会出栈,否则一些全局变量就访问不到了。
接下来,由 Promise 产生的微任务按照队列先后顺序依次被推入函数调用栈执行,直到微任务队列清空。此环节执行完毕,控制台会打印 4,5。
微任务队列被清空后,会进行一次 UI 渲染操作,这样第一轮任务就完成了。接下来再去检查宏任务队列,如果宏任务队列不为空,则提取一个宏任务进入函数调用栈执行,开始执行第二轮任务。这个宏任务执行过程中可能又会产生新的宏任务和微任务,然后继续执行微任务,检查宏任务,直到两个任务队列彻底清空,这个循环检查和执行任务的过程就是事件循环。
这里宏任务和微任务的区别有两个:
- 宏任务先执行,第一个宏任务就是全局代码,宏任务与微任务交替执行
- 宏任务是一个一个执行,微任务是一整列一次执行完毕
所以当 Promise.then 的回调都执行完成后,最后执行 setTimeout 的回调,打印出 2,因此开头的实例代码打印顺序是:
1,3,6,4,5,2
综上所述,事件循环的大体流程是:一个宏任务 -> 一组微任务 -> 一个宏任务 -> 一组微任务 ...
2.3.5 执行上下文与 this
上节在讲事件循环的时候我们说到,若想代码执行,则需要将全局代码或函数推入调用栈。那么为什么将代码推入函数调用栈之后就能执行呢?
原因很简单,因为代码被推入函数调用栈之后创建了执行上下文环境,上下文才是真正执行代码的地方 —— 任何代码都在执行上下文中运行。
执行上下文也有分类,主要分为三种:
全局上下文—— 全局代码所处的环境函数上下文—— 函数调用时创建的上下文Eval 上下文(这个几乎已经废弃了,知道即可)
在全局代码作为第一个宏任务进入调用栈之后,就创建了全局上下文环境。全局上下文有两个明显的标志:
全局对象(Window 或 Global)this,指向全局对象
注意:在浏览器环境下全局对象是 Window,Node.js 环境下全局对象是 Global
我们前面说到,全局代码执行之后并不会出栈,按照上下文的解释,就是全局上下文一直存在,因此我们才能在代码中一直访问全局变量和 this。
当然这是默认存在的。如果全局代码中还声明了变量和函数,那么这些变量和函数也会一直随着全局上下文存在。假设下面这段代码运行,我们看一下全局上下文是什么样子:
// test.js
var city = "北京";
var area = "海淀区";
function getAdress() {
return city + area;
}
getAdress();上述代码声明了两个变量一个函数,在全局上下文创建时会被添加到全局对象 Window 下。虽然我们看不到,但是创建的过程是分阶段的,执行上下文的生命周期有两个阶段:
创建阶段—— 初始化变量,函数等执行阶段—— 逐行执行脚本里的代码
创建阶段做的几件事情如下:
- 创建全局对象(Window 或 Global)
- 创建 this ,并指向全局对象
- 将变量和函数放到内存中,变量赋值为 undefined
- 创建作用域链
注意第三步,创建变量后并不是直接赋值,而是先赋值 undefined。因为只一步还没有读取变量值,只是为变量开辟内存空间,并给其赋一个默认值而已。
这也解释了前面介绍的一种情况叫变量提升,为什么会出现变量提升?本质是在执行上下文的创建阶段已经将变量赋值为 undefined,此时代码还未执行,当代码执行时变量已经存在,这才给我们造成了“变量提升”的错觉。
第四步也非常重要 —— 创建作用域链。这一步直接影响到闭包这样的问题,我们后面说。
当创建阶段的准备工作做好之后,接下来进入执行阶段。执行阶段就是我们理解的按先后顺序执行代码,遇到变量赋值时就赋值,遇到函数调用时就调用,也是在这个阶段正式开始了事件循环。
再看上面那段简单的代码,可以按照上下文的两个阶段将其拆分:
// 1. 创建阶段
var city = undefined;
var area = undefined;
function getAdress() {
var country = "中国";
return country + city + area;
}
// 2. 执行阶段
city = "北京";
area = "海淀区";
getAdress();在全局上下文的执行阶段如果遇到函数,那么函数会被推入调用栈执行,此时创建了函数上下文。函数上下文也是分创建和执行两个阶段,与全局上下文基本一致。但是也有区别,我们对比一下:
- 创建时机:全局上下文在运行脚本时被创建,函数上下文在函数调用时被创建
- 创建频率:全局上下文仅在第一次运行创建一次,函数上下文则是调用一次创建一次
- 创建参数:全局上下文创建全局对象(Window),函数上下文创建参数对象(arguments)
- this 指向:全局上下文指向全局对象,函数上下文取决于函数如何被调用
函数调用栈在执行完成后会立刻出栈,同时函数上下文也被销毁,自然函数上下文所包含的变量也不能再被访问,这也是了为什么 JavaScript 访问变量只能访问父级作用域,而不能访问子函数的原因。因为此时子函数要么没有被调用,要么调用完被销毁,函数作用域已经不存在了,自然不能访问到里面的变量。
这里说的作用域,其实就是指变量所处的执行上下文。
介绍完了函数调用栈的创建/销毁逻辑,那么就不得不提一个特殊的场景 —— 闭包。直接看代码:
function funout(a) {
return function funin(b) {
return a + b;
};
}
var funadd = funout(10);
funadd(20); // 30上述代码中,funout 函数执行之后返回了一个新函数,在新函数内使用了 funout 函数的参数(可看作变量)a;当新函数 funadd 调用时,函数 funout 已经调用完毕,按理说函数上下文已经销毁。然而我们竟然还可以在新函数 funadd 内使用已经销毁的变量 a,这是怎么回事?难道 funout 的函数上下文并未销毁?
并不是这样,funout 调用完毕之后函数上下文已经销毁。然而在执行上下文的创建阶段还创建了作用域链,正是这个作用域链,将可能用到的父级函数上下文内的变量存了下来。所以之后虽然父级函数上下文销毁,但是变量依然能够从作用域链中找到。
我们前面说,作用域就是变量所处的执行上下文。这里可以看出它两点区别了:函数执行上下文在函数调用之后必然会销毁,但是作用域却可能被缓存。
到这里,我们 JavaScript 核心原理部分就介绍完了。我们再将执行上下文和事件循环的知识结合,画一张简易的 JavaScript 执行流程图。
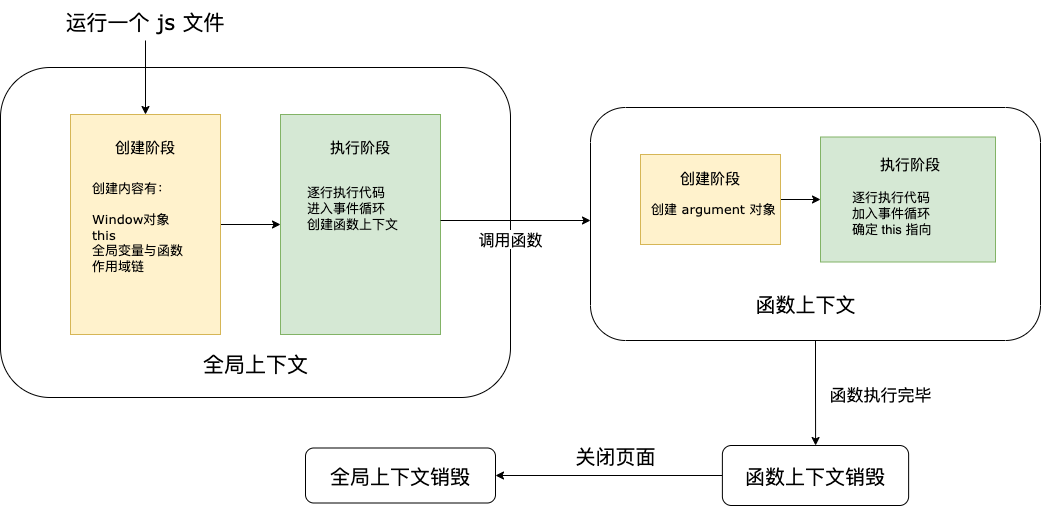
本章小结
本章从更深的角度重新梳理和总结了 HTML、CSS 和 JavaScript 的核心内容。通过学习本章,读者可以更深刻地认识“三驾马车”。基础是进阶的前提,只有夯实基础才能使后面的学习更顺利。
本章的 JavaScript 部分只介绍了核心原理,第 3 章会全面展开介绍,带领读者了解 ES6+、Node.js、TypeScript 等新时代 JavaScript 的强大能力。