12.2 文章管理接口
文章管理接口是博客系统最主要的接口,这组接口设计细节比较多,逻辑稍微复杂一些。但是别担心,我们依然从基本的逻辑梳理开始,将博客集合需要的字段按照“基础字段”和“拓展字段”分开介绍。
首先从文章的基础功能来看,我们需要以下字段:
- title:文章标题,必填。
- intro:文章简介,必填。
- content:文章内容,必填。
- page_view:文章浏览量。
- created_by:文章创建者,必填。
- created_at:文章创建时间。
- updated_at:文章更新时间。
其中 created_by 字段存储的是用户 ID,是文章作者的标识。之后在查询文章信息时可以用这个字段关联查询到用户信息。
创建 model/articles.js 文件,编写文章 Model 模型并导出,代码如下:
const mongoose = require("mongoose");
const { ObjectId } = mongoose.Types;
const articlesSchema = new mongoose.Schema({
title: { type: String, required: true },
intro: { type: String, required: true },
content: { type: String, required: true },
page_view: { type: Number, default: 0 },
created_by: { type: ObjectId, required: true },
created_at: { type: Date, default: Date.now },
updated_at: { type: Date, default: Date.now },
});
const Model = mongoose.model("articles", articlesSchema);
module.exports = Model;拓展字段主要描述文章内容本身之外的数据,如点赞、收藏、评论等。我们要添加的第一个扩展字段是分类,掘金的文章总体共分为八个大类,这八个分类没有必要存数据库,直接定义为静态数据即可。
创建 config/static.js 文件,声明静态的分类数据并导出,代码如下:
const categories = [
{
key: "frontend",
label: "前端",
},
{
key: "backend",
label: "后端",
},
{
key: "android",
label: "安卓",
},
{
key: "ios",
label: "IOS",
},
{
key: "ai",
label: "AI",
},
{
key: "tool",
label: "开发工具",
},
{
key: "life",
label: "代码人生",
},
{
key: "read",
label: "阅读",
},
];
module.exports = {
categories,
};然后在 model/articles.js 中的 Schema 中添加分类字段 category,并使用 enum 限定字段的值为上述分类的 key 值之一,代码如下:
// model/articles.js
const { categories } = require("../config/static");
new mongoose.Schema({
...
category: {
type: String,
enum: categories.map((cate) => cate.key),
required: true,
},
})文章还需要一个标签字段 tags。与分类不同的是标签比较多,需要单独创建一个标签集合,因此 tags 字段的值就是标签 ID 组成的数组。文章发布之前会存在草稿箱,其实我们只需要给文章加一个 status 字段标记当前是否是发布状态即可。两个字段如下:
// model/articles.js
const { ObjectId } = mongoose.Types
new mongoose.Schema({
...
tags: [
{
type: ObjectId,
required: true,
}, // 数组项是 ObjectId
],
status: {
type: Number,
enum: [0, 1], // 0 代表未发布、1 代表已发布
default: 0,
},
})除此之外,最关键的就是点赞和评论数据了。赞和评论我们不在文章集合中创建字段,我们会分别创建点赞和评论的集合,在集合中与文章的 ID 关联绑定,在查询文章时关联查询出对应的赞和评论数据。
12.2.1 创建与发布文章接口
新建路由文件 router/articles.js,然后导入文章 Model,代码如下:
var express = require("express");
var router = express.Router();
var ArtsModel = require("../model/articles");
router.all("/", (req, res) => {
res.send("文章管理API");
});
module.exports = router;在 config/router.js 文件中注册文章路由:
const artRouter = require("../router/articles.js");
const router = (app) => {
...
app.use("/arts", artRouter);
};然后新增创建文章的路由,地址为 “/create”,方法为 POST,代码如下:
router.post('/create', async (req, res, next) => {
let body = req.body
try {
let result = await ArtsModel.create(body)
res.send(result)
} catch (err) {
...
}
})创建接口比较简单,直接接收参数入库就好了,字段规则交给 mongoose 去验证。model.create() 方法执行后会返回创建的数据。
现在我们测试一下添加文章的结果,如图所示:
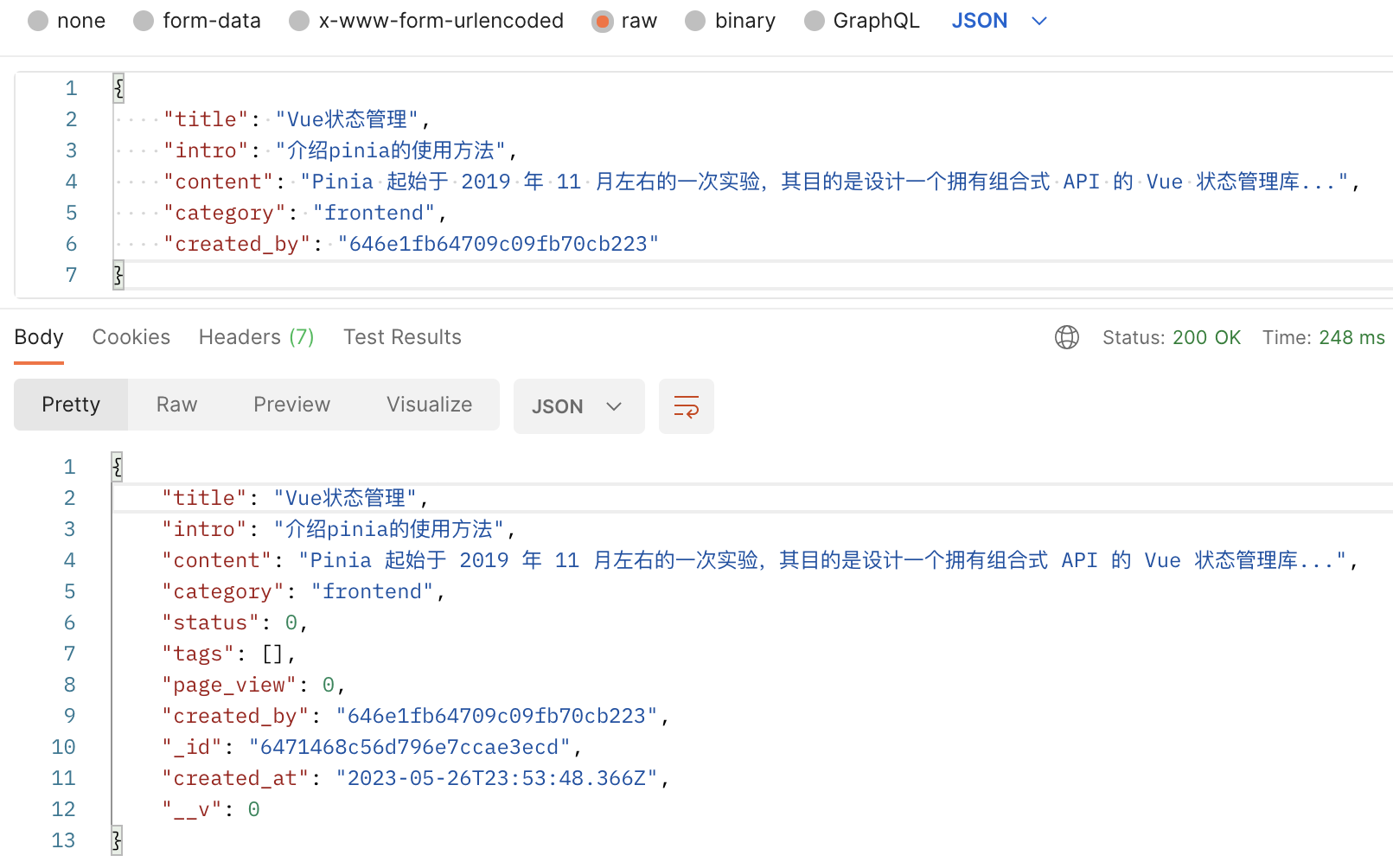
创建文章成功了,但默认是在草稿箱内,我们还需要发布文章。
发布文章,只需要将文章的 status 字段从 0 改为 1。我们创建一个发布文章的路由,地址为 “/publish”,方法为 POST,代码如下:
// 发布文章
router.post('/publish/:id', async (req, res, next) => {
let { id } = req.params
try {
let result = await ArtsModel.findByIdAndUpdate(id, { status: 1 })
res.send(result)
} catch (err) {
...
}
})12.2.2 修改与删除文章接口
修改文章接口,允许修改文章标题、基本介绍、文章内容、分类、标签等基础字段,同时修改成功后要自动更新 updated_at 字段。修改接口要用 PUT 方法,创建路由如下:
router.put('/update/:id', async (req, res, next) => {
let body = req.body
let { id } = req.params
try {
let allow_keys = ['title', 'intro', 'content', 'category', 'tags']
Object.keys(body).forEach(key => {
if (!allow_keys.includes(key)) {
delete body[key]
}
})
if (Object.keys(body).length == 0) {
return res.status(400).send({
message: '请传入要更新的数据',
})
}
body.updated_at = new Date()
await ArtsModel.findByIdAndUpdate(id, body)
res.send({ message: '更新成功' })
} catch (err) {
...
}
})更新文章与更新用户信息的验证逻辑类似,做参数过滤处理。代码中更新时间时,直接用 new Date() 获取当前时间即可。
最后再写一个删除文章的接口,这个比较简单,根据 ID 删除就好。创建路由 “/emove/:id”,方法为 DELETE,代码如下:
router.delete('/remove/:id', async (req, res, next) => {
let { id } = req.params
try {
let result = await ArtsModel.findByIdAndDelete(id)
if (result) {
res.send({ message: '删除成功' })
} else {
res.status(400).send({ message: '文档未找到,删除失败' })
}
} catch (err) {
...
}
})代码中使用 model.findByIdAndDelete() 方法删除文档,根据返回结果判断是否删除成功。
12.2.3 文章的赞和收藏接口
经过分析,文章的赞和收藏需要存储的字段几乎是一样的,并且在掘金的消息中心有一个“赞和收藏”的消息列表,所以我们可以把赞和收藏放在一个集合中,用一个 type 字段区分。
从扩展性的角度考虑,会发现沸点中也有赞,而赞的逻辑基本都一样,所以我们也可以把沸点的赞存储在这个集合中,然后用另一个字段区分。
按照上面的逻辑,我们新设计一个名为 praises 的集合,其字段信息如下:
- target_id:目标,文章或沸点的 ID。
- target_type:目标类型,1 表示文章,2 表示沸点。
- target_user:目标用户,文章或沸点的创建者 ID。
- type:类型,1 表示点赞,2 表示收藏。
- created_by:赞或评论的创建者 ID。
- created_at:创建时间。
上面的几个字段清晰地描述了赞和收藏的信息,查询时可以根据类型、目标类型、目标用户等多个维度筛选和统计数据。
创建 mondel/praises.js 文件,依据上述字段编写赞和收藏的 Model,代码如下:
const praisesSchema = new mongoose.Schema({
target_id: { type: ObjectId, required: true }, // 文章或沸点ID
target_type: {
type: Number,
enum: [1, 2],
required: true,
}, // 1: 文章,2: 沸点
target_user: { type: ObjectId, required: true }, // 目标用户ID
type: {
type: Number,
enum: [1, 2],
default: 1,
required: true,
}, // 1: 点赞,2: 收藏
created_by: { type: ObjectId, required: true },
created_at: { type: Date, default: Date.now },
});
const Model = mongoose.model("praises", praisesSchema);然后创建 router/praises.js 文件,编写赞和收藏的路由代码。点赞和取消点赞本质上就是创建和删除数据,并且点赞数据不能重复创建,因为一个人不能对一篇文章赞两次。
所以,为了防止重复创建数据,并且减少接口数量,我们把点赞(收藏)和取消点赞(收藏)写成一个接口,接收同样的参数。如果根据参数查到了数据,那么就删除,执行取消操作,反之就创建数据。
创建路由名为 “/toggle”,方法为 POST,代码如下:
var PraisModel = require("../model/praises");
router.post("/toggle", async (req, res, next) => {
let body = req.body;
try {
let { target_user, target_id, created_by, target_type } = body;
if (!target_id || !target_type || !target_user || !created_by) {
return res.status(400).send({ message: "参数缺失" });
}
let action = "delete";
let result = await PraisModel.findOneAndDelete(body);
if (!result) {
action = "create";
result = await PraisModel.create(body);
}
res.send({
action,
message: action == "create" ? "创建成功" : "取消成功",
});
} catch (err) {
next(err);
}
});上述代码首先验证参数,然后尝试使用 model.findOneAndDelete() 删除文档。如果没有找到文档,则返回空,删除自然也不会执行,此时我们就创建文档,最终将结果输出。
这样的好处是,只需调用一个接口,它会自动判断出应该创建还是删除。接着在 config/router.js 文件中注册路由:
const praisRouter = require("../router/praises.js");
const router = (app) => {
...
app.use("/praises", praisRouter);
};现在该接口就可以调用了。我们为上一步创建的文章添加一个赞,测试结果如下:
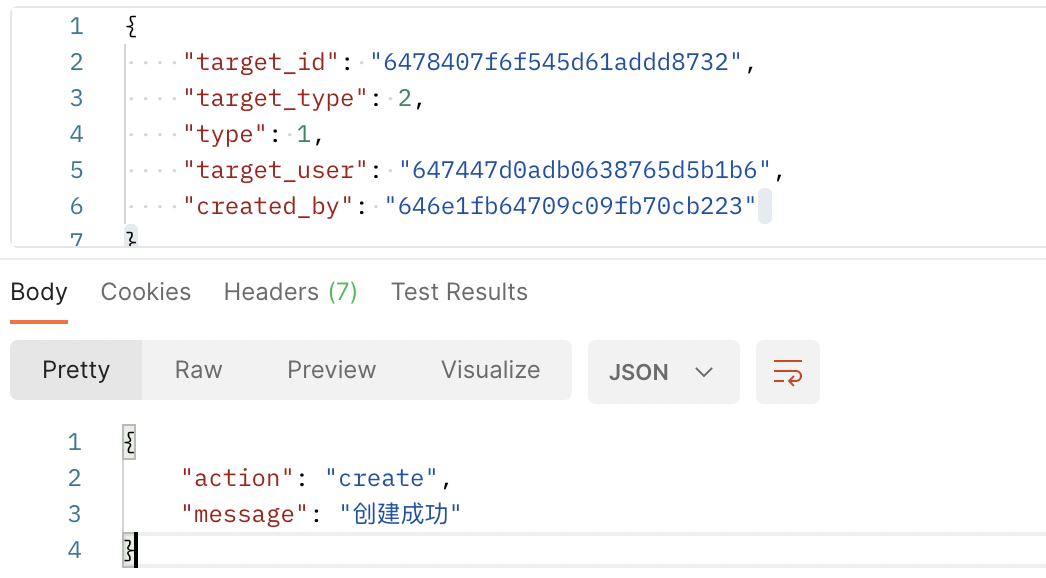
参数不变,再请求一次,可以看到赞已经取消了,如图所示:
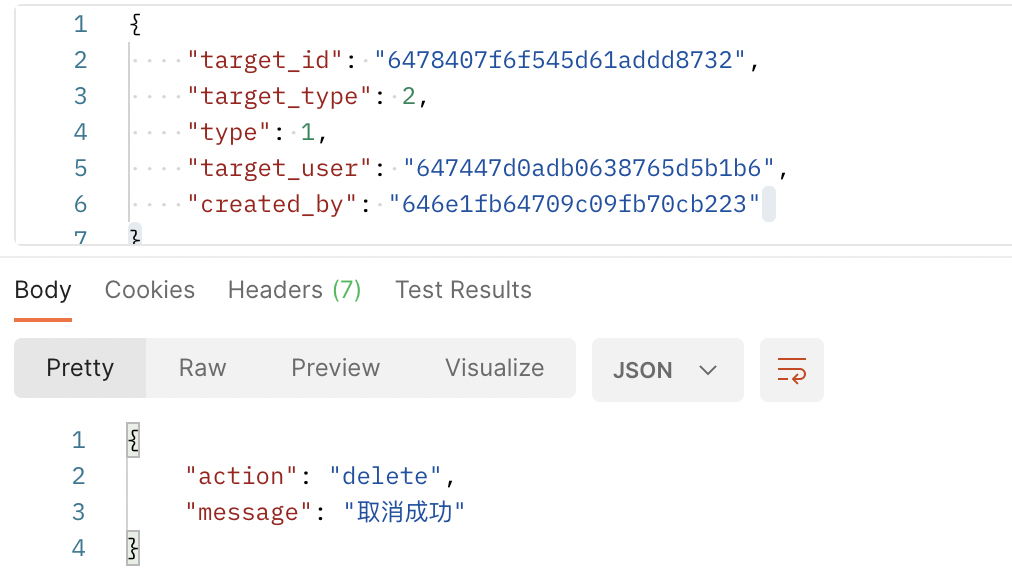
创建和取消实现之后,暂时不需要写列表接口,因为获取赞和收藏的数据会在查询文章、沸点和个人消息时关联查询,不需要单独接口。
12.2.4 文章的评论接口
文章的评论同样与沸点通用,并且在消息中心页面有评论列表,所以我们也设计一个单独的集合来存储文章和沸点的评论数据。
我特别观察了下掘金的评论,发现这个评论的逻辑还是有点意思的。整体上评论可以分为三种类型:
- 对文章的评论。
- 对文章下评论的评论。
- 对文章下评论的评论的回复。
截一个掘金的评论界面,如图 12-2 所示:

那么我们设计的集合,要同时兼顾这三种类型,并且用尽可能少的字段来实现。集合名为 comments,字段信息如下:
- source_id:来源,文章或沸点的 ID。
- source_type:来源类型,1 表示文章,2 表示沸点。
- type:评论类型,source 表示内容,comment 表示评论,reply 表示回复。
- parent_id:父级评论的 ID(type 不为 source 时有值)。
- reply_id:回复某个评论的 ID(type 为 reply 时有值)。
- target_user:评论对象创建者的 ID。
- content:评论内容。
- created_by: 评论创建者。
- created_at: 评论创建时间。
特别说明一下,type 字段对应上述的三种评论类型,而 target_user 字段的值随类型而变。当 type 为以下三种不同的值时,target_user 所表示的含义如下:
- source:文章或沸点的创建者 ID。
- comment:父级评论的创建者 ID。
- reply:回复的评论的创建者 ID。
现在我们创建 model/comments.js 文件,编写模型内容如下:
const commentsSchema = new mongoose.Schema({
source_id: { type: ObjectId, required: true },
source_type: { type: Number, enum: [1, 2], required: true },
type: {
type: String,
enum: ["source", "comment", "reply"],
required: true,
},
parent_id: {
type: ObjectId,
default: null,
required() {
return this.type != "source";
},
},
reply_id: {
type: ObjectId,
default: null,
required() {
return this.type == "reply";
},
},
target_user: { type: ObjectId, required: true },
content: { type: String, required: true },
created_by: { type: ObjectId, required: true },
created_at: { type: Date, default: Date.now },
});
const Model = mongoose.model("comments", commentsSchema);上面代码中你会发现,parent_id 和 reply_id 两个字段的 required 条件是一个函数,它的值是根据 type 字段的不同而动态变化的,这种写法可以让字段验证逻辑更严谨。
注意:Scheme 中的约束方法(如:required()) 不可以写成箭头函数,那样会使 this 指向失效。
继续创建路由文件 router/comments.js,添加一个创建评论的路由如下:
// router/comments.js
var CommsModel = require("../model/comments");
// 创建评论
router.post("/create", async (req, res, next) => {
let body = req.body;
try {
let result = await CommsModel.create(body)
res.send(result);
} catch (err) {
...
}
});然后在 config/router.js 文件中注册路由:
const commsRouter = require("../router/comments.js");
const router = (app) => {
...
app.use("/comments", commsRouter);
};接着测试一下该接口,可以看到请求结果正常,如图所示:
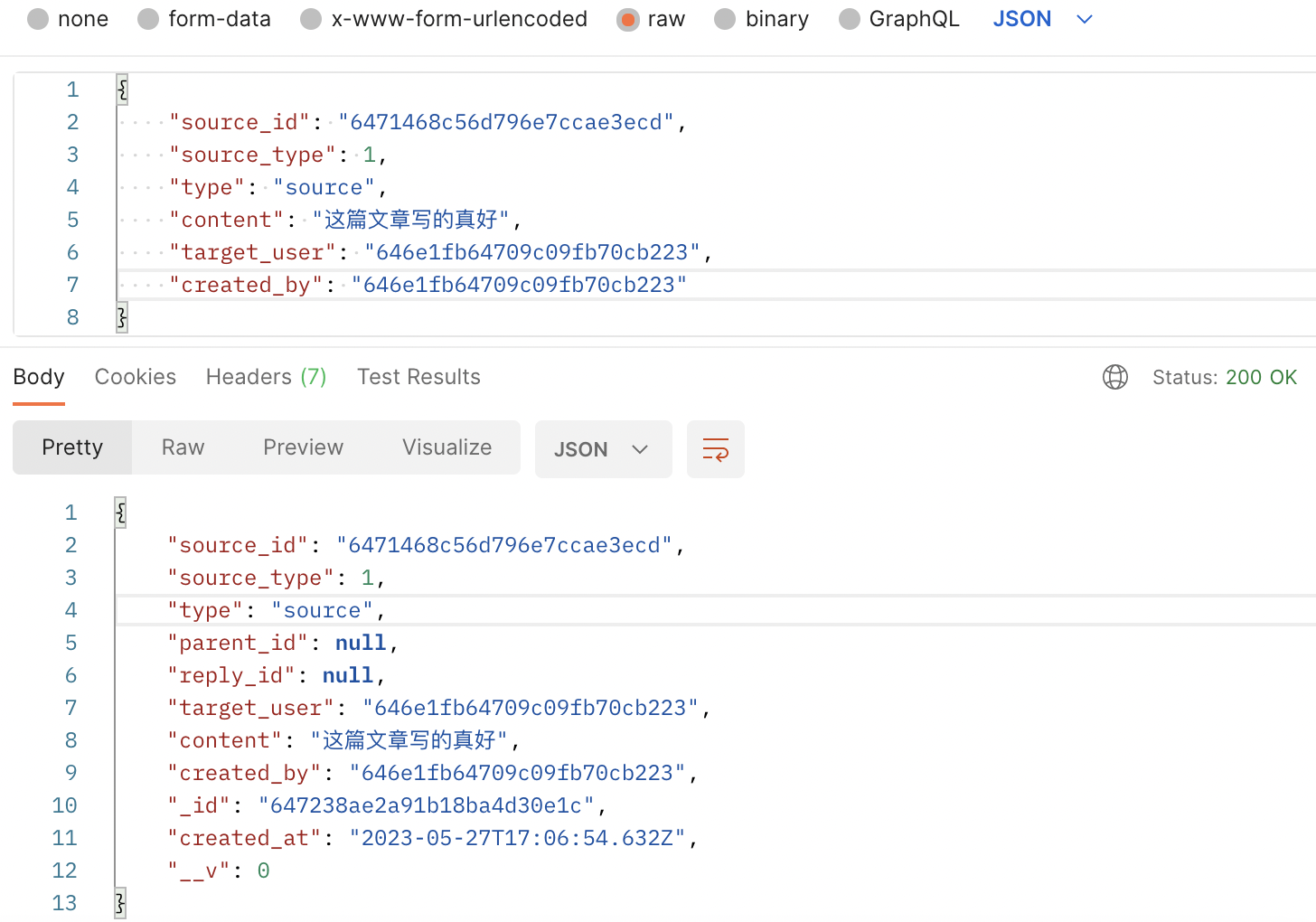
接下来写评论列表接口,这个接口是我们写的第一个需要多集合关联查询的复杂接口。如图 xxx 所示,可以看到评论列表是按层级展示的,并且展示创建者的用户信息,以及回复对象的信息。此时就需要使用高级查询聚合管道(aggregate)来实现了。
我们先看第一版的代码,aggregate 的使用方法如下:
router.get('/list/:source_id', async (req, res, next) => {
let { source_id } = req.params
try {
let lists = await CommsModel.aggregate([
{ $match: { source_id: ObjectId(source_id) } },
{
$lookup: {
from: 'users',
localField: 'created_by',
foreignField: '_id',
as: 'created_by',
},
},
])
res.send(lists)
} catch (err) {
...
}
})上述代码中,第一条管道的操作符是 $match,表示从评论集合中匹配数据,条件是集合文档的 source_id 等于请求参数 source_id。
第二个管道的操作符 $lookup 就是关联查询的操作符了,它有 4 个属性,含义如下:
- from:从哪个集合关联。
- localField: 当前集合的关联字段。
- foreignField: 被关联集合的关联字段,
- as:关联查询后数据存放的字段。
所以代码中第二个管道的含义,就是关联 users 集合,关联条件是 comments.created_by == users._id,并将关联查询后的用户文档放在 created_by 字段下,我们查看结果:
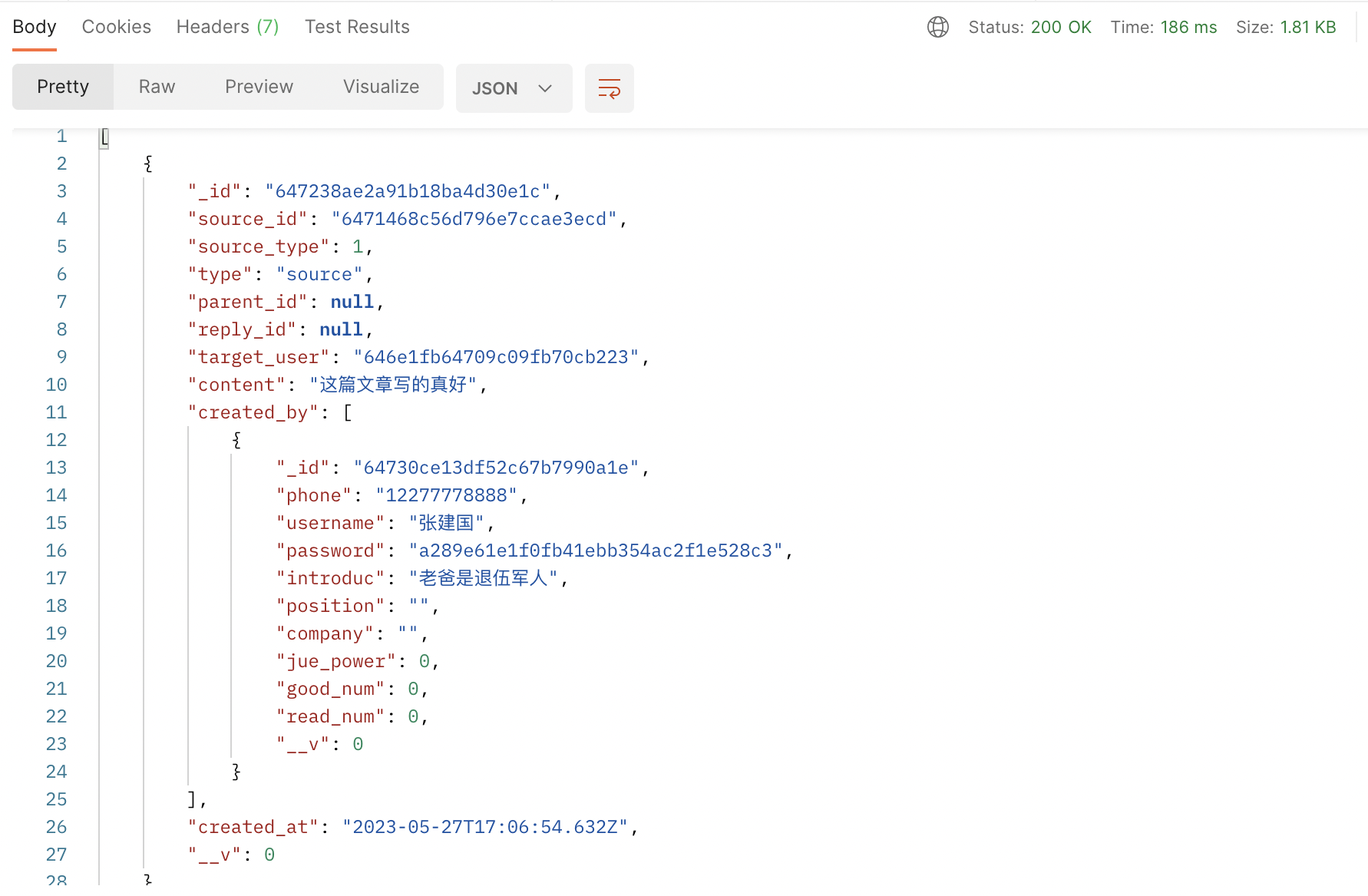
可以看到 created_by 字段已经从用户 ID 变成用户信息了,但我们希望它是一个对象而不是数组,并且返回字段太多需要精简,我们写两个处理函数如下:
// 字段过滤
const filterJson = (json, keys) => {
return Object.fromEntries(
Object.entries(json).filter(row => keys.includes(row[0]))
)
}
// 字段判空处理
const handle = item => {
let created_by =
item.created_by.length > 0
? filterJson(item.created_by[0], ['_id', 'username', 'position'])
: null
return {
_id: item._id,
content: item.content,
created_by,
}接着使用 handle() 方法遍历处理用户数据,并且将返回值处理为符合评论页面的层级格式。代码如下:
let result = lists
.filter((list) => list.type == "source")
.map((row) => {
return {
...handle(row),
replies: lists
.filter((list) => list.parent_id == row._id.toString())
.map((row) => {
return {
...handle(row),
reply_id: row.reply_id,
};
}),
};
});
res.send(lists);现在再调用评论列表接口,可以看到返回格式已经是我们需要的层级结构了:
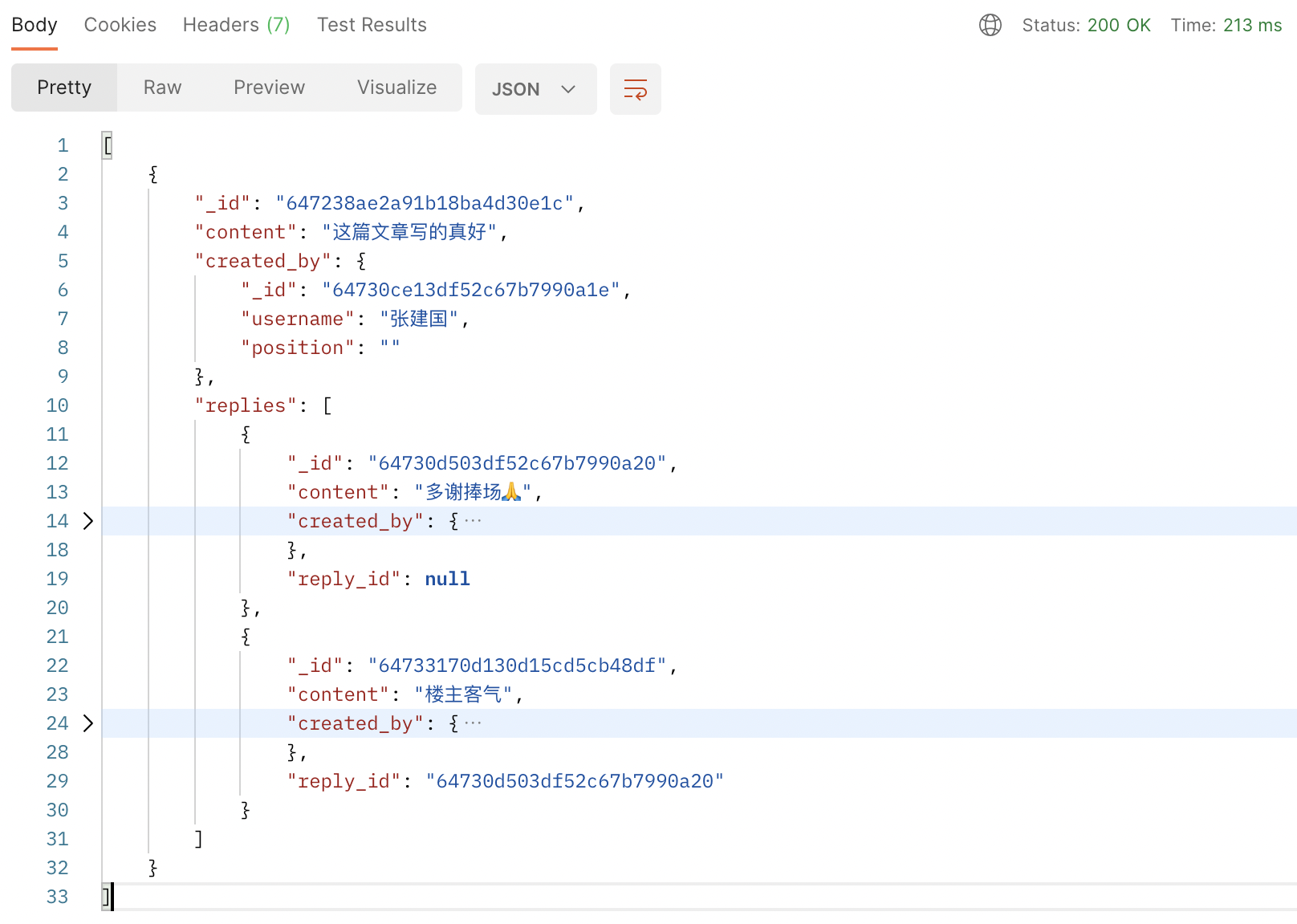
最后再写一个简单的删除单条评论的接口,代码如下:
router.delete('/remove/:id', async (req, res, next) => {
let { id } = req.params
try {
let result = await CommsModel.findByIdAndDelete(id)
if (result) {
res.send({ message: '删除成功' })
} else {
res.status(400).send({ message: '文档未找到,删除失败' })
}
} catch (err) {
...
}
})12.2.5 文章的列表接口
有了赞和评论的集合,我们现在就可以编写完整的文章列表接口了。首页的文章列表只包含了赞和评论的数量,因此我们使用聚合管道查询文章数据,并关联查询到对应的赞和评论数据。初次之外,该接口还需要分页,我们要以分页结构返回数据。
创建文章列表路由,地址为 “/list”,方法为 GET。代码如下:
router.get('/list', async (req, res, next) => {
let { user_id } = req.query
try {
let result = await ArtsModel.aggregate([
...
])
res.send(result)
} catch (err) {
next(err)
}
})上面代码中使用了聚合管道高级查询,一共有 5 条管道,稍微复杂一些。具体的每条管道分别做了什么,我们分开来介绍。
- 管道一:关联查询评论集合。
关联查询使用 $lookup 管道阶段,代码如下:
{
$lookup: {
from: 'comments',
localField: '_id',
foreignField: 'source_id',
as: 'comments',
},
},上面代码的意思是:关联 comments 集合,关联条件是 articles._id 等于 comments.source_id,关联查询的返回值放在 comments 字段下。
- 管道二:关联查询点赞集合。
查询点赞集合同样使用 $lookup 管道阶段,原理与管道一一致,代码如下:
{
$lookup: {
from: 'praises',
localField: '_id',
foreignField: 'target_id',
as: 'praises',
},
}经过两条管道的处理,每项文章数据都多了 comments 和 praises 两个字段,值为数组。
- 管道三:处理点赞和评论数据。
使用 $addFields 管道阶段来添加或修改已有的字段,代码如下:
{
$addFields: {
praises: {
$filter: {
input: '$praises',
as: 'arrs',
cond: { $eq: ['$$arrs.type', 1] },
},
},
comments: {
$size: '$comments',
},
},
}因为文章列表只需要展示评论数量,所以用 $size 操作符获取 comments 字段的长度并覆盖该字段;点赞集合中可能包含收藏数据,所以用 $filter 操作符过滤一下。
“$filter” 操作符支持三个属性,分别如下:
- input:输入的源数组。
- as:将源数组自定义一个变量名。
- cond:过滤条件。代码中的条件是文档的 type 字段等于 1 。
- 管道四:返回点赞数量和当前用户是否点赞。
将上个管道输出的 praises 字段取长度变成点赞数量,再添加 is_praise 字段表示当前用户是否点赞,需要依据传入的 user_id 参数判断,代码如下:
{
$addFields: {
is_praise: {
$in: [ObjectId(user_id), '$praises.created_by'],
},
praises: {
$size: '$praises',
},
},
}“$in” 操作符的值是一个数组,判断条件是第一个数组项的值在第二个数组项(也是一个数组)之间。
经过这四个管道的处理,我们可以获得想要的数据了。测试该接口,返回结果如图所示:
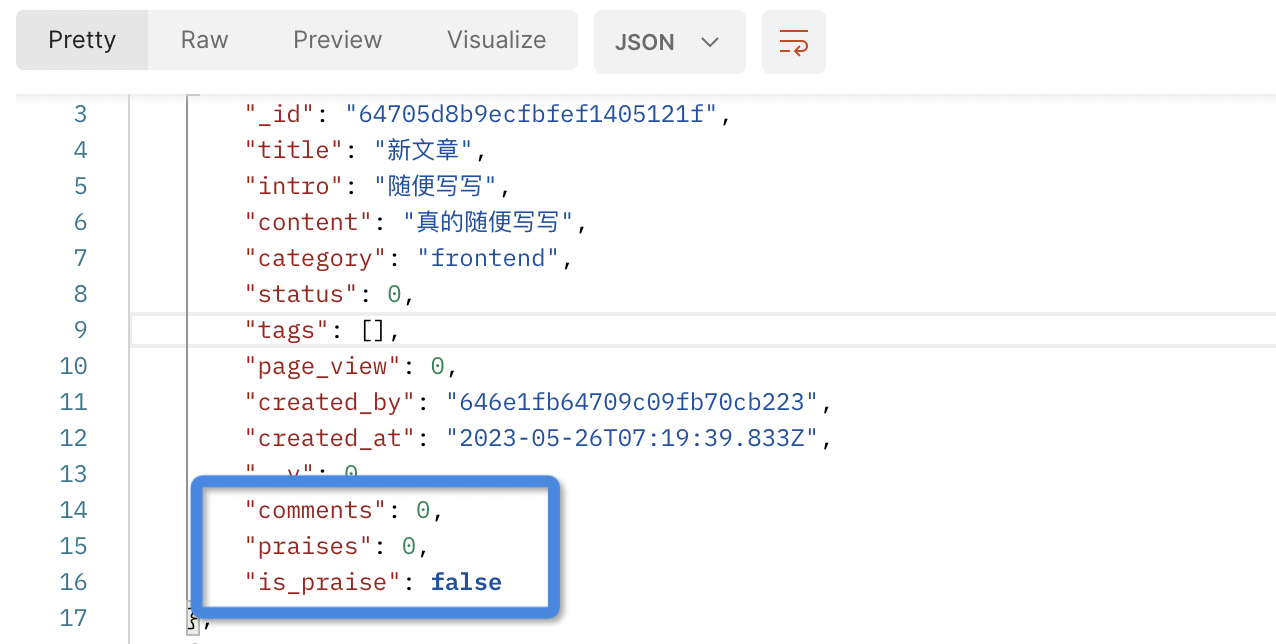
12.2.6 文章的详情接口
文章详情接口的开发方式与文章列表类似,都是使用聚合管道关联多个集合查询。从文章详情页面看,需要关联的数据包括用户、点赞、收藏、评论。因为我们已经有一个单独的评论列表接口,所以文章详情接口里不包含评论数据,这样只需要关联 users 和 praises 两个集合。
创建文章详情路由,地址为 “/detail/:id”,方法为 GET。代码如下:
router.get("/detail/:id", async (req, res, next) => {
let { id } = req.params;
let { user_id } = req.query;
try {
let result = await ArtsModel.aggregate([
{
$match: {
_id: ObjectId(id),
},
},
{
$lookup: {
from: "praises",
localField: "_id",
foreignField: "target_id",
as: "praises",
},
},
{
$lookup: {
from: "users",
localField: "created_by",
foreignField: "_id",
as: "user",
},
},
{
$addFields: {
praises: {
$filter: {
input: "$praises",
as: "arrs",
cond: { $eq: ["$$arrs.type", 1] },
},
},
stars: {
$filter: {
input: "$praises",
as: "arrs",
cond: { $eq: ["$$arrs.type", 2] },
},
},
user: {
$first: "$user",
},
},
},
{
$addFields: {
is_praise: {
$in: [ObjectId(user_id), "$praises.created_by"],
},
praises: {
$size: "$praises",
},
is_start: {
$in: [ObjectId(user_id), "$stars.created_by"],
},
stars: {
$size: "$stars",
},
},
},
{
$unset: ["user.password", "user.__v"],
},
]);
res.send(result[0]);
} catch (err) {
next(err);
}
});如果理解了文章列表接口的管道逻辑,就能看懂上述代码中的每个管道都做了什么。经过上面的几个管道处理,我们在根据文章 ID 查询到文章详情数据时,添加了以下几个字段:
- user:当前文章的创建者数据。
- praises:文章的点赞数量。
- stars:文章的收藏数量。
- is_praise:我是否收藏。
- is_start:我是否点赞。
“$unset” 操作符都作用是删除不必要的返回字段,我们删除了用户的密码和另一个无用字段。$first 操作符的作用是返回数组的第一项。测试上面的接口,可以看到返回结果如下:
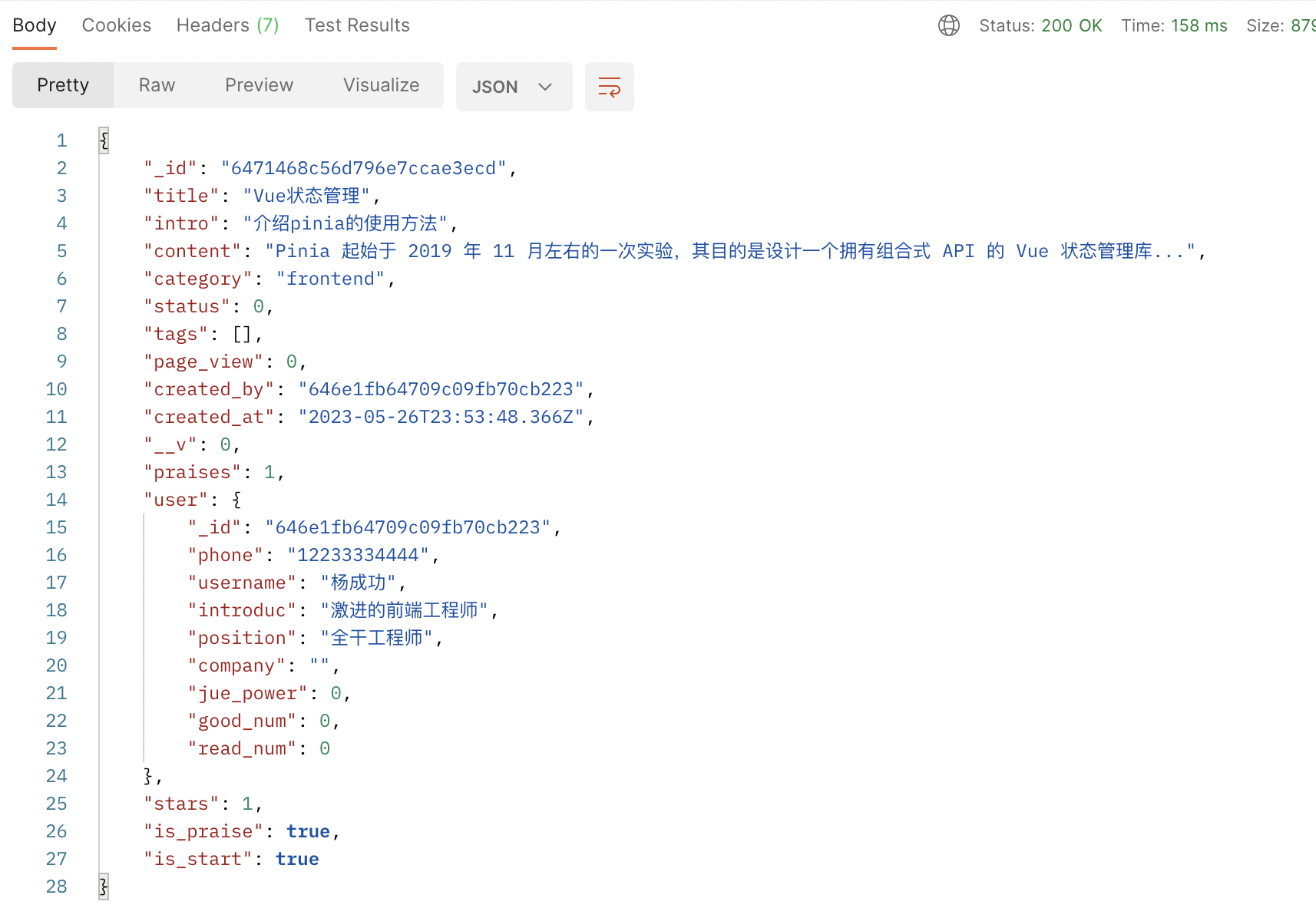
再通过评论列表接口获取到文章的评论数量和列表,我们的文章详情页需要展示的数据就全部获取到了。