12.5 应用完善与部署
首先要恭喜大家,经过前面的好几个环节,我们已经将用户管理、文章管理、沸点管理、消息管理、关注/评论等全部接口开发完成了。如果你跟到了这一步,我要为你竖起大拇指,你太棒了!
业务功能虽然全都实现了,但是从全局来讲,我们还有许多没有处理的细节。这些细节是 API 架构方面的通用设计,不涉及具体业务,我们分别来处理一下。
12.5.1 登录验证
我们前面写的所有列表或修改接口,当前用户的 user_id 都是明文传递,这样一个很明显的问题,就是你可以执行任何用户的操作,这显然是不正确的。为此,我们需要做登录验证。
所谓登录验证,就是在登录之后创建一个 token 表示当前用户的令牌,请求接口时需要携带这个令牌并经过验证,否则接口会拒绝访问。有了这个令牌后,我们可以自动解析出改用户的 user_id,避免明文传递不安全的问题。
目前登录验证的常用方案是 JWT,也就是将用户信息加密后生成 token 令牌,请求接口时携带在请求头中。实现该逻辑,我们首先要安装一个第三方包:
$ yarn add express-jwt然后创建 utils/jwt.js 文件,编写生成 token 和 验证 token 两个方法并导出,代码如下:
// utils/jwt.js
const { expressjwt: exjwt } = require("express-jwt");
var jwt = require("jsonwebtoken");
// 密匙
const SECRET_KEY = "alifn_jueblog_jwt_8756";
// 生成jwt
function genoJwt(data) {
let token = jwt.sign(data, SECRET_KEY, { expiresIn: "7d" });
return token;
}
// 验证jwt
function verifyJwt() {
return exjwt({
secret: SECRET_KEY,
algorithms: ["HS256"],
requestProperty: "auth",
});
}
module.exports = {
genoJwt,
verifyJwt,
};代码中的常量 SECRET_KEY 是一个密钥,用于加密解密,加密方法可以将信息加密生成 token,解密方法可以从 token 中解出用户信息。接着我们改造登录接口,登录成功返回 token,添加代码如下:
// router/user.js
const { genoJwt } = require('../utils/jwt')
...
if (result) {
let { _id, username } = result
let token = genoJwt({ _id, username })
res.send({
code: 200,
data: result,
token: token,
})
} else {
res.send({
code: 20001,
message: '用户名或密码错误',
})
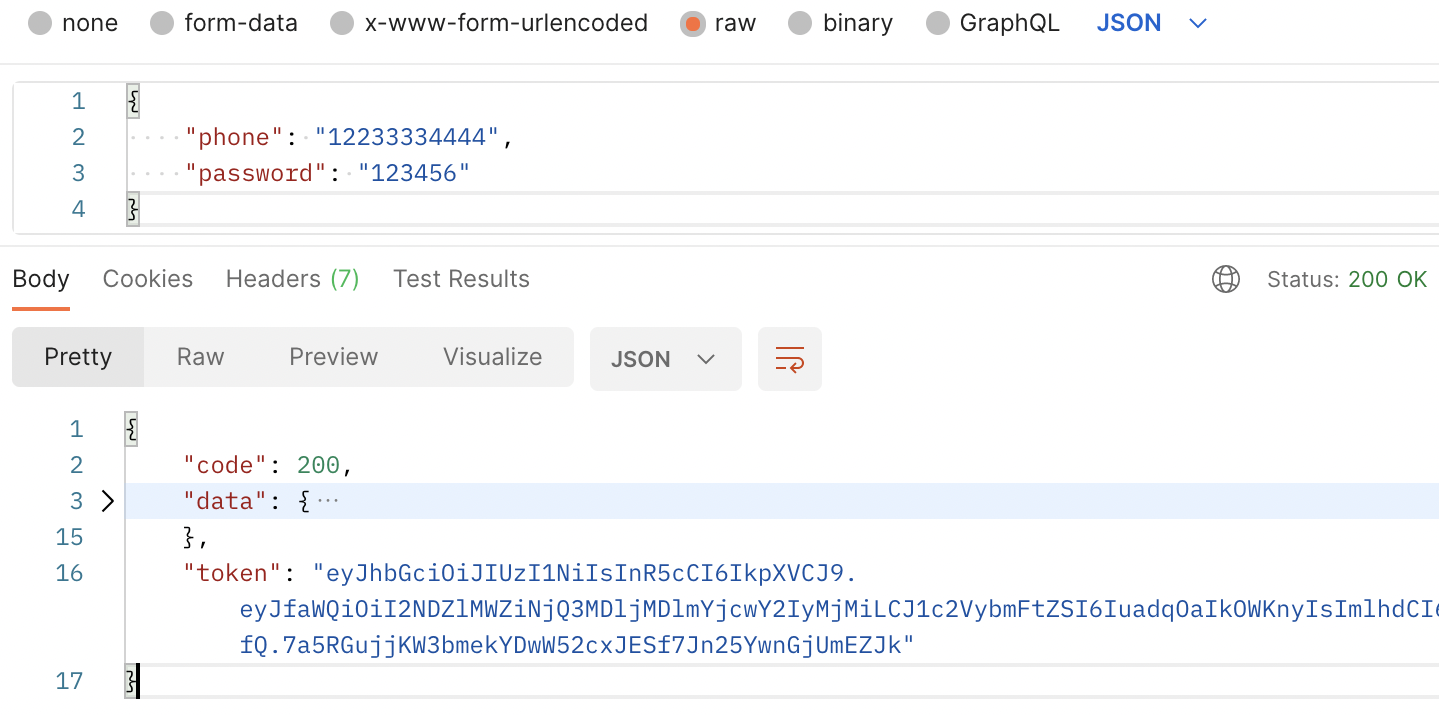
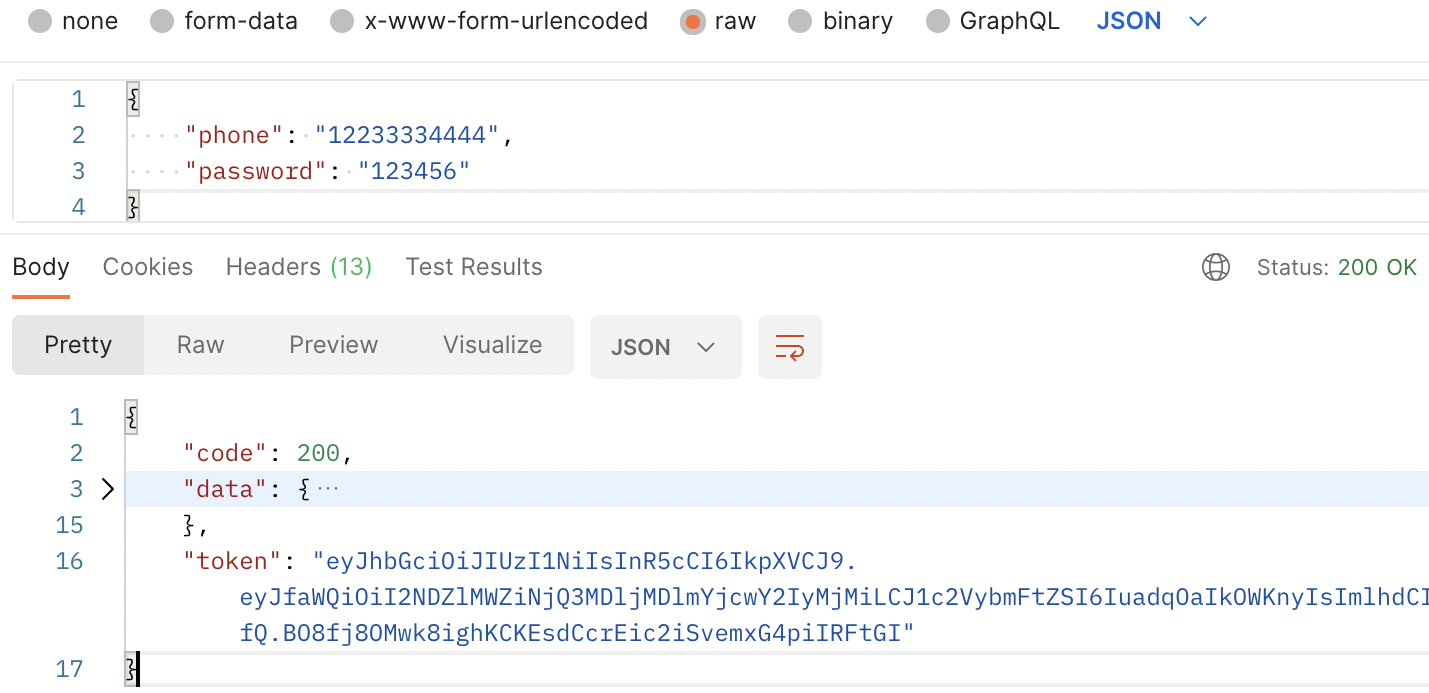
}我们基于用户的 _id 和 username 两个字段生成 token。重新测试登录接口,可以看到 token 已输出,结果如下:
然后在入口文件 index.js 中加入验证 token 的中间件(需要在路由之前),代码如下:
const { verifyJwt } = require("./utils/jwt");
app.use(
verifyJwt().unless({
path: ["/users/create", "/users/login"],
})
);代码中 path 属性下添加绕过验证的路由。首先注册和登录接口是必须绕过的,因为注册登录时肯定没有 token,必须绕过保证用户可以正常登录,其他路由可以自定义。
现在随便测试一个除注册登录之外的接口,可以看到返回 401 状态并输出错误信息,如图所示:

这是告诉我们没有登录不允许调用接口。怎么办呢?这一步前端就比较熟悉了,在请求时将登录返回的 token 加到请求头中,我们添加后测试结果如下:
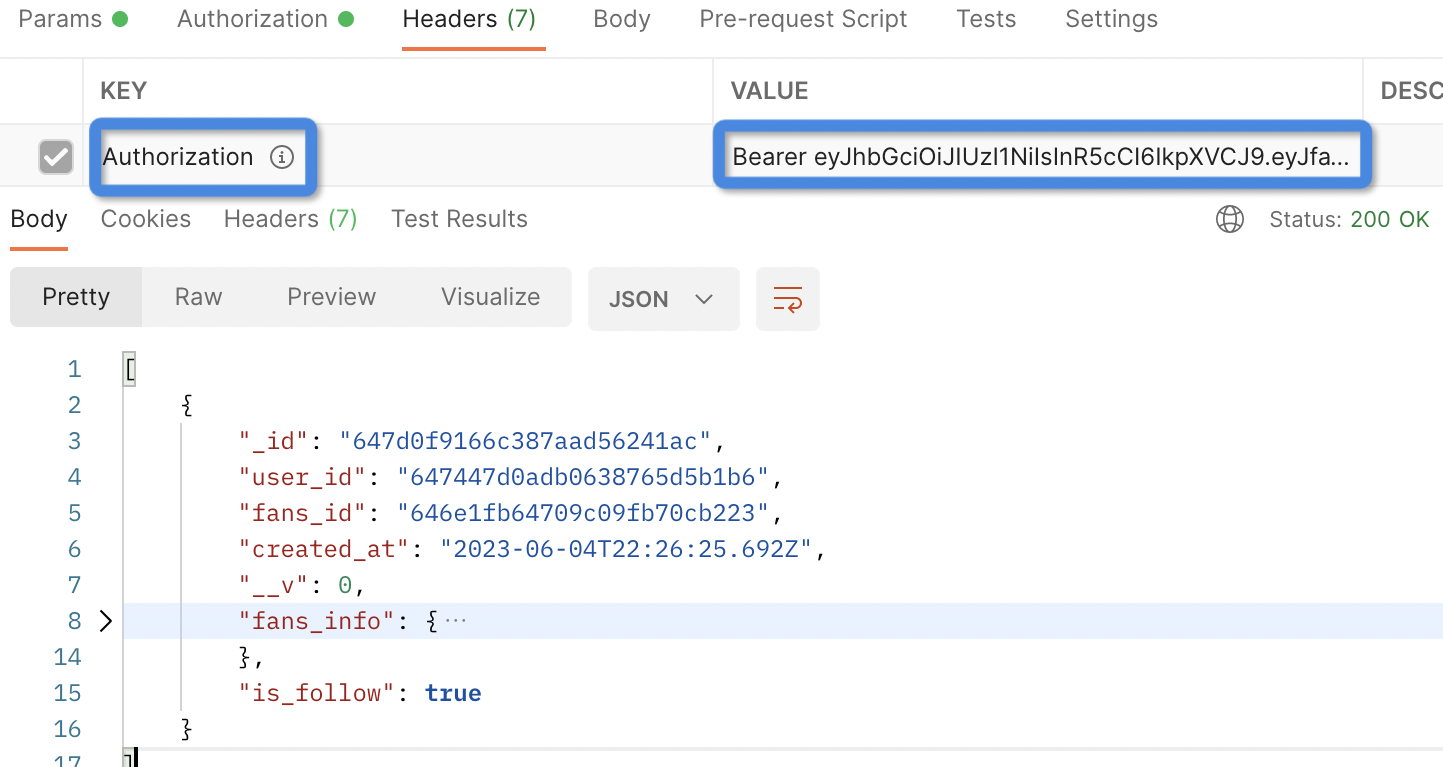
可以看到,接口正常返回 200,说明验证通过。
有了 token 之后,我们就可以在路由中通过 “req.auth” 获取到 token 中的用户 ID。因此之前编写的所有接口中,有需要传递当前用户 ID 的地方,都要改成这样:
router.get("/lists", async (req, res, next) => {
// 删除这行:let { user_id } = req.query
// 用下面这行代替:
let user_id = req.auth._id;
});这样一方面减少了参数传递,另一方面也避免了其他用户信息被修改的隐患,此时接口的安全和验证才算完成了。
12.5.2 列表分页
为了减少多余篇幅,我们之前的所有列表接口都没有加分页,因为分页的逻辑都是一样的,所以这里统一介绍。大多数分页是在聚合管道中,主要由两个管道阶段控制查询分页:
- $skip: 跳过多少条数据,实现分页逻辑。
- $limit: 限制返回条数,控制每页的数量。
在有分页的 GET 请求中还要从 URL 中接收统一的分页参数,一共有两个:
- per_page:每页的条数,默认 10 条。
- page:当前页码,默认第 1 页。
在请求中获取统一分页参数代码如下:
router.get("/lists", async (req, res, next) => {
let query = req.query;
let per_page = +query.per_page || 10;
let page = +query.page || 1;
let skip = (page - 1) * per_page; // 跳过多少条数据
});特别要说明代码中的 skip 变量,根据当前页和每页的条数,计算出查询时要跳过多少页,供后面查询分页时使用。
以沸点列表为例,首先要获取到查询结果的总数量:
let where = {};
let total = await StmsgsModel.count(where).skip(skip);然后在聚合管道中的最后两个管道进行分页查询:
let result = await StmsgsModel.aggregate([
...,
{ $skip: skip },
{
$limit: per_page,
},
])最终将两个查询的结果汇总为一个对象返回,分页信息放在 mete 属性下,实际数据赋值给 data 属性,代码如下:
res.send({
meta: {
total,
page,
per_page,
},
data: result,
});测试该接口,返回结果如图所示。
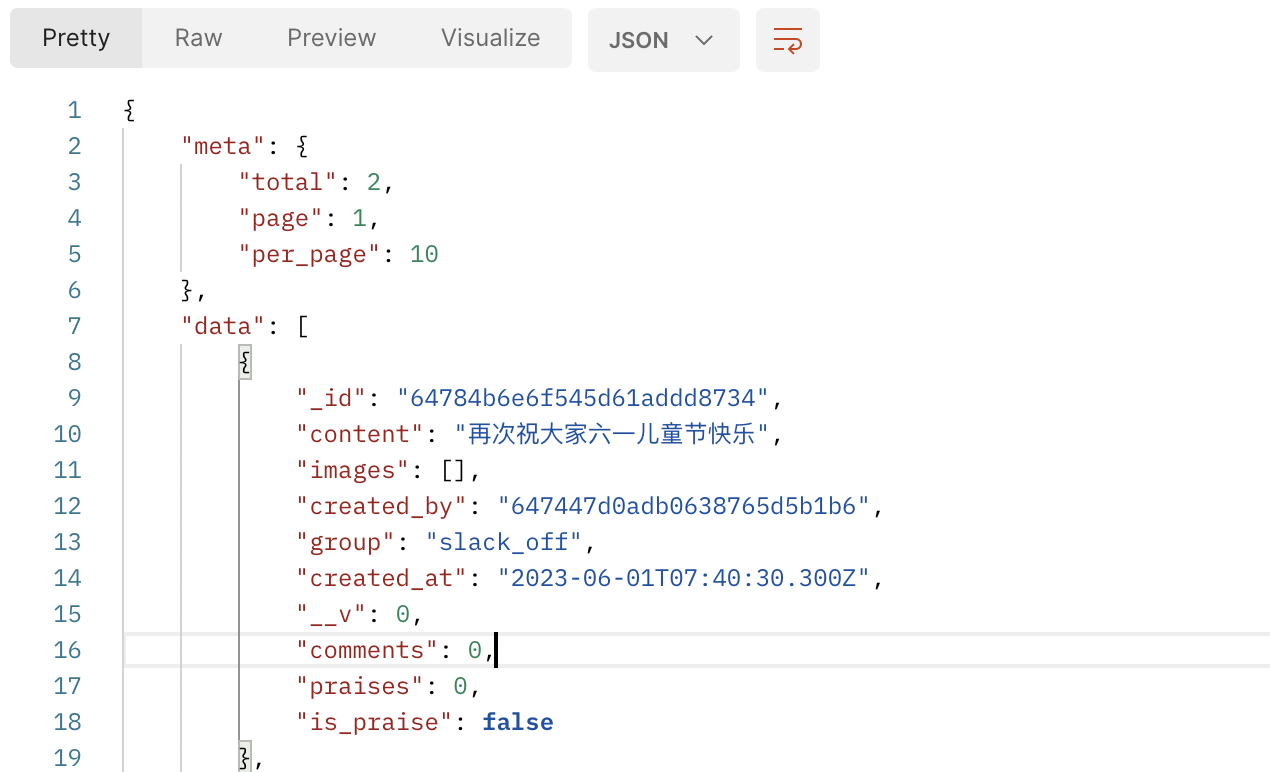
这就是我们标准的分页返回格式。其他需要分页的接口如文章列表、沸点列表、消息列表等均按照这种方式改造,不再赘述。
12.5.3 统一处理路由错误
前面我们在每个路由的 catch 部分都做了错误处理,并且错误处理的代码几乎完全一样。还记得吗?错误处理的代码是这样子:
try {
...
} catch (err) {
let code = err.name == 'ValidationError' ? 400 : 500
let { name, message } = err
res.status(code).send({
name,
message,
})
}但是每个路由都要加这段代码,设计上很不优雅。之前在应用中添加的最后一个中间件就是错误处理中间件,如果能让路由异常进入这个中间件,就能省去这些重复工作。
那么如何进入错误处理中间件呢?其实很简单,只要切换中间件的 next() 方法传入一个错误参数,就可以直接进入错误处理中间件,如下:
var err = new Error();
next(err);而路由的 catch 部分正好捕获的是一个错误,所以我们可以直接转到错误处理中间件:
router.get('/list', (req, res, next)=> {
try {
...
} catch (err) {
next(err)
}
})现在我们在应用的错误处理中间件中解析 error 对象,并将路由的验证逻辑搬到这里,最终将错误处理中间件改造如下:
app.use((err, req, res, next) => {
let err400 = ["ValidationError", "CastError"];
let code = err400.includes(err.name) ? 400 : err.status || 500;
res.status(code).send({
name: err.name,
message: err.message,
});
});代码中主要的逻辑是设置响应状态码,变量 err400 中存放了需要返回 400 状态码的错误名称,这部分可以根据实际情况自定义。其他异常可以先获取错误码,没有错误码直接返回 500。
12.5.4 代码发布云函数
API 接口已经全部开发完成了,现在我们要将最终代码上传到云函数。
云函数的项目启动不依赖 pm2,而是使用 “npm run start” 命令,情确保该命令在 package.json 中配置,如下:
{
"scripts": {
"start": "node ./index.js"
}
}浏览器打开云函数 blog-fun 的详情页,找到上传按钮,我们把整个文件夹上传,上传后点击“保存并部署”按钮,如图所示:
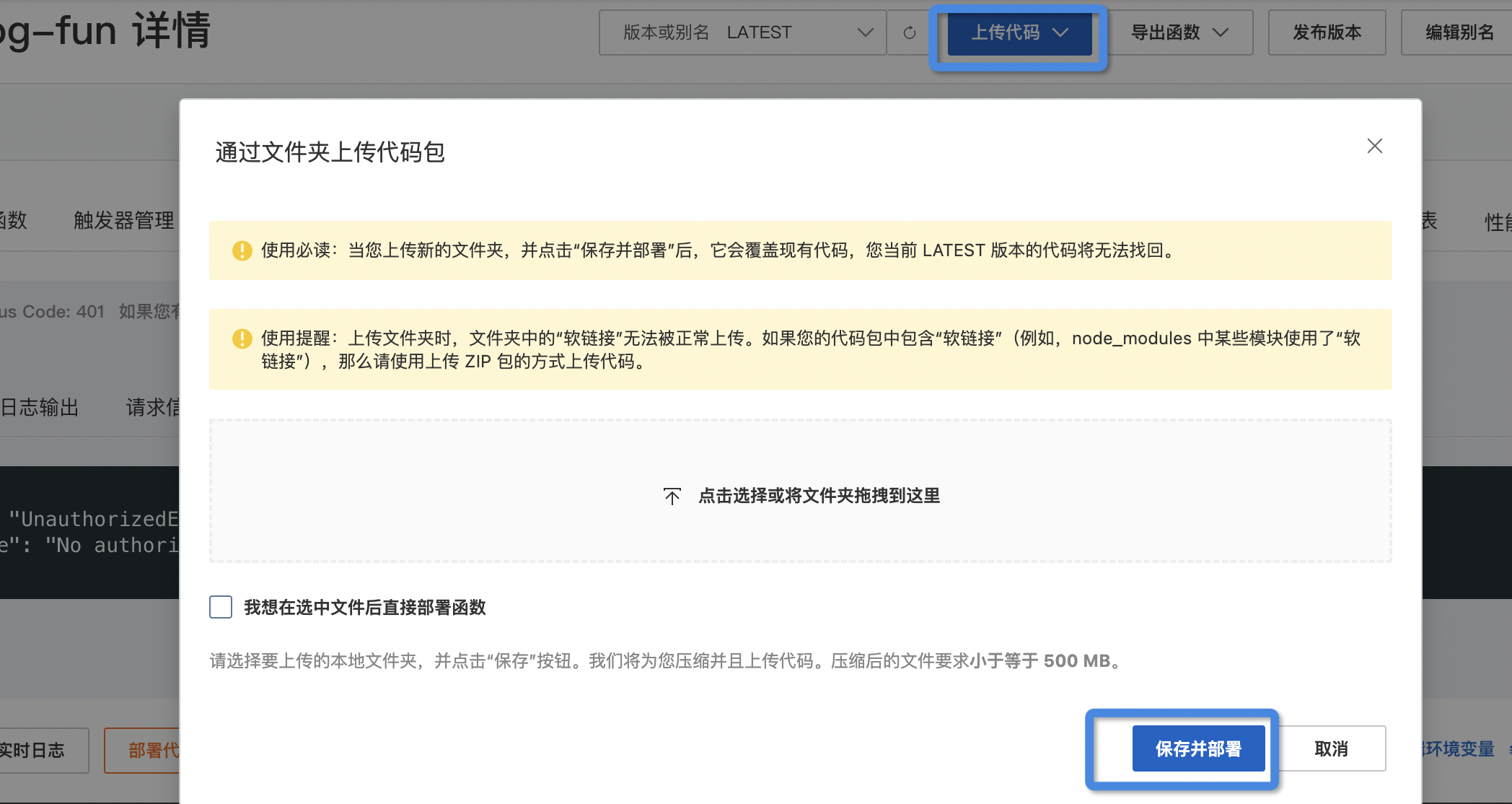
保存后稍等一会就会部署成功。现在尝试请求云函数的公网 URL,可以看到返回结果符合预期。以登录接口为例,线上 URL 请求结果如图所示:
部署方式很简单吧,直接上传文件夹即可。不过这里有一个非常重要的优化项,就是我们要上传 node_modules 文件夹,这会成倍增大函数的体积。在详情页可以看到上传后的函数体积为 4.2M,如图所示。

云函数有一个冷启动的概念,就是函数在调用时会频繁启动和卸载,如果代码体积大则会大大增加接口的响应时间。阿里云提供了一个 “层” 的概念,可以将 npm 依赖包缓存,抽出函数之外,从而提高函数性能。
12.5.5 创建层缓存依赖
在函数计算的控制台首页左侧菜单中,找到“高级功能/层管理” 菜单,点击“创建层”按钮,输入信息如图所示:

选项中的“兼容运行时”和“构建环境”请按照图中的选择。我们把 package.json 中的依赖项拿过来放到这里,然后点击创建层,等待创建成功。
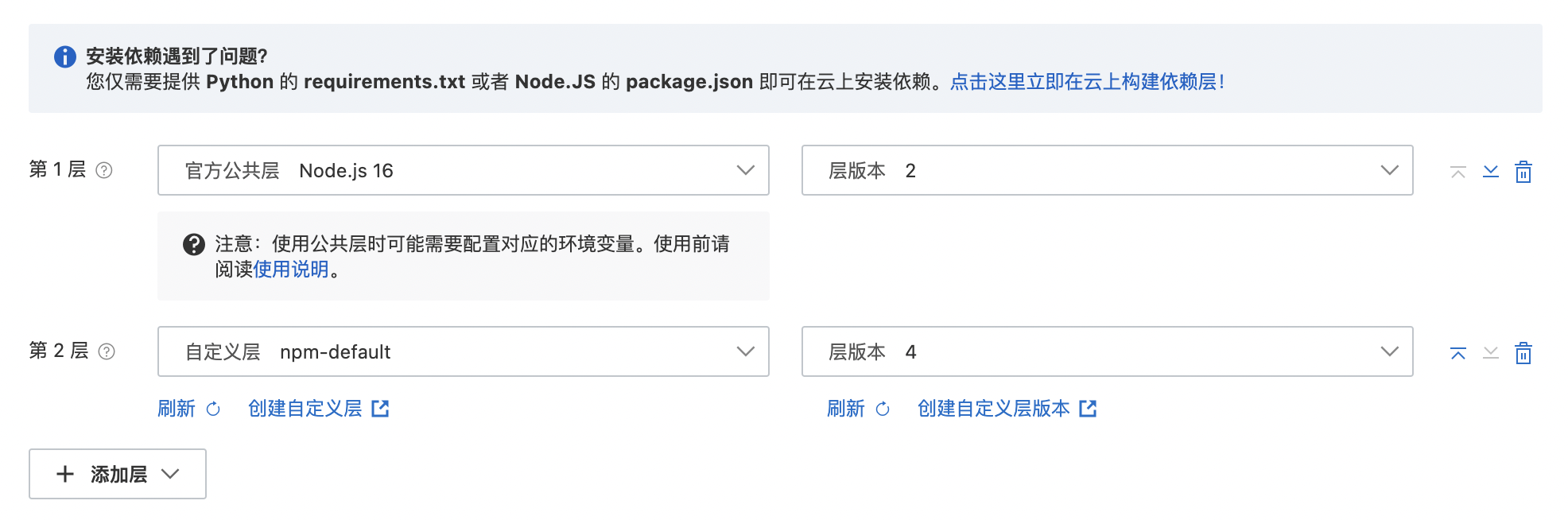
成功后进入函数详情页面,在编辑器右上方有一个“编辑层”按钮,点击按钮会出现弹框,然后点击“添加层->添加自定义层”,选择我们创建的层和对应的版本,如图所示:
现在在 Web 编辑器中删除 node_modules 文件夹并点击部署代码,然后继续测试接口,接口会正常响应,说明函数此时不依赖 node_modules 文件夹了。再看函数体积如图所示:

从 4M 到 26k,函数体积减少了一百多倍,响应速度提升非常明显。
本章小结
本章是纯粹的实战开发,严格按照需求分析开发各个模块的接口。在实战过程中,我们根据不同的场景介绍了 Express 和 MongoDB 的不同用法,并使用接口实际返回结果验证,这样大家可以更快速地理解具体的代码逻辑,特别是复杂的聚合管道查询。
开发接口时是在本地开发测试,完成后我们上线接口,将代码部署到了云函数。下一章就可以进入前端开发环节,将本章开发的接口接入并调试了。